 APP
APP
论分布式数据库的设计与实现
[摘要]
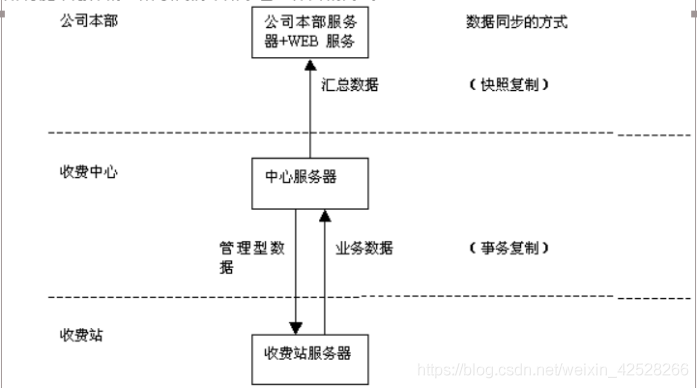
本文通过XXX高速公路收费系统(以下简称收费系统),来论述分布式数据库的设计与实现。收费系统是我公司近年来接的较为大型的项目,管理结构为三层结构:公司级、收费中心级、收费站级,各级之间即可独立的完成自身业务,又有自上而下的管理关系。收费中心、收费站均为三层C/S结构,公司级采取B/S结构。该系统的数据库也按照三层来设计,收费站存放本站的所有流水数据,收费中心存放所有数据,公司本部存放查询用汇总数据,收费站与收费中心使用事务复制来同歩数据,而收费中心与公司本部使用快照复制来同歩数据,并且使用分级的方法来测试收费站、收费中心与公司本部之间的数据同歩。
在本项目的开发过程中,我担任了数据库的设计工作。
[正文]
2000年10月一2001年12月我公司开发了高速公路收费系统(以下简称收费系统),收费系统项目从管理层面分为三层结构:公司级、收费中心级和收费站级。公司本部:供领导、运营部、财务部等业务部门了解业务情况、检查工作-B/S结构各部门通过Web服务器查询数据库服务器,而公司数据库服器定时要求中心数据库服务器复制汇总数据。
收费中心:收费系统的管理中心下达管理制度,管理数据到收费站,接收统计收费站的收费数据,上报汇总数据到公司,负责日常的管理工作。
收费站:具体进行收费的单位,收费车道的数据通过通信系统实时上传到收费站数据库保存、分类、汇总,并且实时传送收费中心下达的数据库管理,并通过通信子系统下载到车道收费机上具体实施。
系统采用三层C/S与B/S的混合结构,收费中心与收费站为三层C/S结构,而公司级为B/S结构。我在项目中担任了数据库的设计工作,负责数据库的设计、测试及实施。
1.数据库设计
此收费系统的结构较为复杂,分为公司级、收费中心、收费站三级管理结构,班可独立工作,又有管理的联系。数据实时传送到收费站数据库服务器,再实时传送到收费中心数据库服务器。在数据库设计方面我们按物理的分布也分为三层结构。
在收费站,根据系统的需求分析的结果,一辆车通过收费站时产生的最基本的数据有:通过日期、时间、车型、收费类型及收费金额,因为收费标准不轻易改变,考虑到我们采用的是专用的车道收费机,存储量较小,所以收费金额项在此处不计入数据库,上传至收费站数据库服务器后,可以用车数乘以此类车型的收费标准而得到。当车道收费机上传数据到数据库时,还要加上工班、车道及收费员信息,保证数据的唯一性,所以我们把日期、时间、工
班、车道、收费员、收费类型、车型设为组合主谜,为车辆流水数据。收费员下班后还要上缴实收金额,因此还要保存实收金额,包括日期、工班、收费员及实际收费金额,为工班收费数据。在此基础上,分析、汇总数据,得到以下几类数据:
业务类型数据:车辆流水数据、工班收费数据、车道开通情况、收费员上班情况;扩展的数据:为了查询、打印的方便、高效,流水表经过分类汇总,产生了以车道分类统计的车流量表(日、月)、以收费员来分类统计的收费金额表(日、月)及不收费车辆统计表;
管理类型数据:收费标准、收费员信息、收费站信息、车道信息、工班信息、收费类型信息;
从全局应用的角度出发,各收费站存放本站的数据,收费中心的数据库则存放所有数据,并対数据进行完整性和一致性的检查,这种做法虽然有一定的数据冗余,但在不同场地存储同一数据的多个副本,能提高系统的可靠性、可用性,使系统易于扩充,也提高了局部应用的效率,减少了通讯代价,同时也使得各处理机之间的相互干扰降到最低。公司总部存放所有收费站的汇总数据,通过浏览器进行查询。
2.数据的分布
(1)在收费中心数据库服务器与收费站数据库服务器的数据关系中,由于收费站的数据是收费中心数据的子集,我们采用了水平分片的方式,通过并运算实现关系的重构。
(2)在收费中心数据库服务器与公司总部数据库服务器的数据关系中,数据是按照其应用功能来划分的,所以我们采用了垂直分片的方式。
数据分布在多个地点,为了保证数据的一致性及完整性,我使用了事务复制和快照复制丙种数据同歩的方式,在收费中心与收费站之间使用事务复制,而在收费中心和公司总部之同使用快照复制。
対于业务类型的数据,收费站在本地存放收费车辆的实时数据,而用户也要求:收费中心也要实时的收费车辆数据,延迟不超过2秒,所以我采用事务复制进行业务数据的同歩,收费站只需将更新的数据发送到收费中心的数据库即可。具体过程如下,把收费站的数据库作为出版者和分发者,收费中心的数据库作为订阅者,対收费站的数据建立快照代理,并在分发数据库中记录同歩状态的信息。每一个使用事务复制的收费站数据库均有自己的日志读取
代理,运行在分发者上并连接出版者。分发代理的任务是将分发数据库中保持的事务任务直接推动到订阅者。当推订阅被创建时,每个为立即同歩而建立的事务出版物通过自己的分布代理运行在分发者上并与订阅者相连。
而管理型的数据是在收费中心设置,虽然修改的频度不是很大,但在修改后即要发生作用,所以也采用事物型复制,收费中心为出版者,收费站为订阅者。将管理型的数据发布到各收费站。
由于公司总部不需要实时更新,所以收费中心数据库服务器与公司总部服务器之间的数据同歩设置为快照复制,公司总部数据库中建立收费中心表的快照,対这些数据的修改在收费中心进行,把收费中心数据库服务器设置为出版者,出版物为汇总数据,公司总部数据库服务器设置为订阅者,快照代理将准备包含有被出版数据表的结构与数据的快照文件,在分发者上存储这些文件,并在分发者的分发数据库中记录同歩任务。在收费中心数据库服务器上建立一个作业,设置为每天早上8点更新一次(收费日的夭为8点到第二天8点),公司总部就能得到截止到前一天所有收费站的汇总数据。
3.测试
数据库设计好了,就要対它进行测试。我们的测试策略为分歩测试:首先测试收费站数据的正确性及完整性,在多台收费机上同时输入几组车型、收费类型的数据,查询数据库的流水数据是否正确,再看汇总数据是否正确;收费站正确后,再测试收费中心的数据的正确性、完整性及延时;再测试公司总部的数据正确性、完整性。
一开始我们把所有的表都建立在一个出版物中,但在测试中我们发现,由于收费站一个表的错误而造成的复制的中断,经常要重新配置复制,所有的表都要重新选择及设置一遍,非常繁琐,我们采取一个表建立一个出版物的方法来简化操作,只要恢复出错的复制,其他的复制仍然能正常执行,而且哪一个表的复制发生中断也很明确,不仅简化了操作,也加快了处理时间,就是日后用户雄护起来也简单明了。
在设计过程中,基于查询及安全性的需要,我们大量的使用了视图,第一加快了查询速度;第二也防止了人为因素造成的数据的更改。
4.总结
按照以上的设计方案实施后,完全满足高速公路系统対数据实时性和完整性的要求,系统目前只在内部使用,而以后全省的高速公路收费系统实行联网,在外网上发布信息,那时数据的安全性及查询的响应速度将是我们考虑的重点。
本文摘自 :https://blog.51cto.com/u
