 APP
APP
-
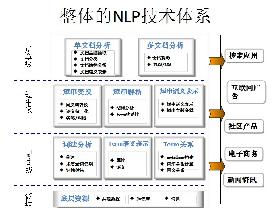
- 自然语言处理
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。语言是人类区别其他动物的本质特性。在所有生物中,只有人类才具有语言能力。人类的多种智能都与语言有着密切的关系。人类的逻辑思维以语言为形式,人类的绝大部分知识也是以语言文字的形式记载和流传下来的。因而,它也是人工智能的一个重要,甚至核心部分。
用自然语言与计算机进行通信,这是人们长期以来所追求的。因为它既有明显的实际意义,同时也有重要的理论意义:人们可以用自己最习惯的语言来使用计算机,而无需再花大量的时间和精力去学习不很自然和习惯的各种计算机语言;人们也可通过它进一步了解人类的语言能力和智能的机制。
实现人机间自然语言通信意味着要使计算机既能理解自然语言文本的意义,也能以自然语言文本来表达给定的意图、思想等。前者称为自然语言理解,后者称为自然语言生成。因此,自然语言处理大体包括了自然语言理解和自然语言生成两个部分。历史上对自然语言理解研究得较多,而对自然语言生成研究得较少。但这种状况已有所改变。
无论实现自然语言理解,还是自然语言生成,都远不如人们原来想象的那么简单,而是十分困难的。从现有的理论和技术现状看,通用的、高质量的自然语言处理系统,仍然是较长期的努力目标,但是针对一定应用,具有相当自然语言处理能力的实用系统已经出现,有些已商品化,甚至开始产业化。典型的例子有:多语种数据库和专家系统的自然语言接口、各种机器翻译系统、全文信息检索系统、自动文摘系统等。
自然语言处理,即实现人机间自然语言通信,或实现自然语言理解和自然语言生成是十分困难的。造成困难的根本原因是自然语言文本和对话的各个层次上广泛存在的各种各样的歧义性或多义性(ambiguity)。
一个中文文本从形式上看是由汉字(包括标点符号等)组成的一个字符串。由字可组成词,由词可组成词组,由词组可组成句子,进而由一些句子组成段、节、章、篇。无论在上述的各种层次:字(符)、词、词组、句子、段,……还是在下一层次向上一层次转变中都存在着歧义和多义现象,即形式上一样的一段字符串,在不同的场景或不同的语境下,可以理解成不同的词串、词组串等,并有不同的意义。一般情况下,它们中的大多数都是可以根据相应的语境和场景的规定而得到解决的。也就是说,从总体上说,并不存在歧义。这也就是我们平时并不感到自然语言歧义,和能用自然语言进行正确交流的原因。但是一方面,我们也看到,为了消解歧义,是需要极其大量的知识和进行推理的。如何将这些知识较完整地加以收集和整理出来;又如何找到合适的形式,将它们存入计算机系统中去;以及如何有效地利用它们来消除歧义,都是工作量极大且十分困难的工作。这不是少数人短时期内可以完成的,还有待长期的、系统的工作。
以上说的是,一个中文文本或一个汉字(含标点符号等)串可能有多个含义。它是自然语言理解中的主要困难和障碍。反过来,一个相同或相近的意义同样可以用多个中文文本或多个汉字串来表示。
因此,自然语言的形式(字符串)与其意义之间是一种多对多的关系。其实这也正是自然语言的魅力所在。但从计算机处理的角度看,我们必须消除歧义,而且有人认为它正是自然语言理解中的中心问题,即要把带有潜在歧义的自然语言输入转换成某种无歧义的计算机内部表示。
歧义现象的广泛存在使得消除它们需要大量的知识和推理,这就给基于语言学的方法、基于知识的方法带来了巨大的困难,因而以这些方法为主流的自然语言处理研究几十年来一方面在理论和方法方面取得了很多成就,但在能处理大规模真实文本的系统研制方面,成绩并不显著。研制的一些系统大多数是小规模的、研究性的演示系统。
目前存在的问题有两个方面:一方面,迄今为止的语法都限于分析一个孤立的句子,上下文关系和谈话环境对本句的约束和影响还缺乏系统的研究,因此分析歧义、词语省略、代词所指、同一句话在不同场合或由不同的人说出来所具有的不同含义等问题,尚无明确规律可循,需要加强语用学的研究才能逐步解决。另一方面,人理解一个句子不是单凭语法,还运用了大量的有关知识,包括生活知识和专门知识,这些知识无法全部贮存在计算机里。因此一个书面理解系统只能建立在有限的词汇、句型和特定的主题范围内;计算机的贮存量和运转速度大大提高之后,才有可能适当扩大范围.
以上存在的问题成为自然语言理解在机器翻译应用中的主要难题,这也就是当今机器翻译系统的译文质量离理想目标仍相差甚远的原因之一;而译文质量是机译系统成败的关键。中国数学家、语言学家周海中教授曾在经典论文《机器翻译五十年》中指出:要提高机译的质量,首先要解决的是语言本身问题而不是程序设计问题;单靠若干程序来做机译系统,肯定是无法提高机译质量的;另外在人类尚未明了大脑是如何进行语言的模糊识别和逻辑判断的情况下,机译要想达到“信、达、雅”的程度是不可能的。
发展历史
最早的自然语言理解方面的研究工作是机器翻译。1949年,美国人威弗首先提出了机器翻译设计方案。20世纪60年代,国外对机器翻译曾有大规模的研究工作,耗费了巨额费用,但人们当时显然是低估了自然语言的复杂性,语言处理的理论和技术均不成热,所以进展不大。主要的做法是存储两种语言的单词、短语对应译法的大辞典,翻译时一一对应,技术上只是调整语言的同条顺序。但日常生活中语言的翻译远不是如此简单,很多时候还要参考某句话前后的意思。
大约90年代开始,自然语言处理领域发生了巨大的变化。这种变化的两个明显的特征是:
(1)对系统输入,要求研制的自然语言处理系统能处理大规模的真实文本,而不是如以前的研究性系统那样,只能处理很少的词条和典型句子。只有这样,研制的系统才有真正的实用价值。
(2)对系统的输出,鉴于真实地理解自然语言是十分困难的,对系统并不要求能对自然语言文本进行深层的理解,但要能从中抽取有用的信息。例如,对自然语言文本进行自动地提取索引词,过滤,检索,自动提取重要信息,进行自动摘要等等。
同时,由于强调了“大规模”,强调了“真实文本”,下面两方面的基础性工作也得到了重视和加强。
(1)大规模真实语料库的研制。大规模的经过不同深度加工的真实文本的语料库,是研究自然语言统计性质的基础。没有它们,统计方法只能是无源之水。
(2)大规模、信息丰富的词典的编制工作。规模为几万,十几万,甚至几十万词,含有丰富的信息(如包含词的搭配信息)的计算机可用词典对自然语言处理的重要性是很明显的。
相关内容
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。因此,自然语言处理是与人机交互的领域有关的。在自然语言处理面临很多挑战,包括自然语言理解,因此,自然语言处理涉及人机交互的面积。在NLP诸多挑战涉及自然语言理解,即计算机源于人为或自然语言输入的意思,和其他涉及到自然语言生成。
现代NLP算法是基于机器学习,特别是统计机器学习。机器学习范式是不同于一般之前的尝试语言处理。语言处理任务的实现,通常涉及直接用手的大套规则编码。
许多不同类的机器学习算法已应用于自然语言处理任务。这些算法的输入是一大组从输入数据生成的“特征”。一些最早使用的算法,如决策树,产生硬的if-then规则类似于手写的规则,是再普通的系统体系。然而,越来越多的研究集中于统计模型,这使得基于附加实数值的权重,每个输入要素柔软,概率的决策。此类模型具有能够表达许多不同的可能的答案,而不是只有一个相对的确定性,产生更可靠的结果时,这种模型被包括作为较大系统的一个组成部分的优点。
自然语言处理研究逐渐从词汇语义成分的语义转移,进一步的,叙事的理解。然而人类水平的自然语言处理,是一个人工智能完全问题。它是相当于解决中央的人工智能问题使计算机和人一样聪明,或强大的AI。自然语言处理的未来一般也因此密切结合人工智能发展。
内容来自百科网