 APP
APP
主要介绍自己阅读《Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems 》《A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems》
这两篇文章后的一些感悟和梳理 如果有小伙伴感兴趣的话我们可以多多讨论一下
简介
Offline Reinforcement Learning 的中文名是离线强化学习,所谓离线和单机游戏给人的感觉很像:自己玩自己的,不用和别人一起。强化学习中的离线也就意味着你的agent不和外界交互,使用的数据是固定的。
这里有必要重申一下强化学习的on policy 和 off policy 两种方法的区别在于优化的策略和获得数据的策略是否相同,一种是在自己探索的过程中学习,一种是看着别人的经验为自己所用。
分类
说实话,在读《Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems》的时候介绍最多的是重要性采样和策略约束、不确定性限制这类方法。经过多次总结加上看了《A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems》的总结,有了一点自己小小的感悟。
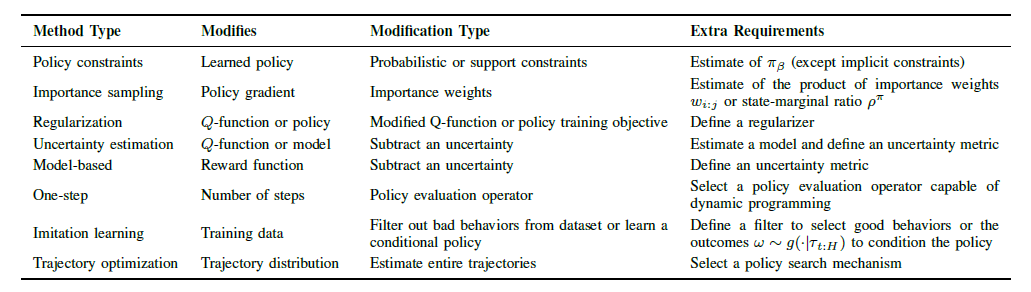
离线RL和普通RL的区别在于数据不能更新,所以在传统解法的基础上会面临新的问题,但大体解决思路不变:依然分为 model-based 和 model-free两大类。
- 如果能够对状态转移和奖励精确建模,那么就可以直接转化为动态规划进行求解。用历史数据拟合出来的模型产生新数据进行计算,如果状态太多不易求解,直接采样估计也是一个很不错的想法。
- 如果对环境模型不够了解的话,就只能根据自己走过的路进行推断和学习了。
在具体求解策略时,也有两种不同的思路:一种是动作状态值函数(状态值函数)通过贪婪策略得解,在得到值函数时根据动作离散和连续又可以分为表格型和函数近似型;另一种是策略梯度,即直接用函数拟合策略,找到合适参数也就找到了好的策略。在这两种方法的基础上,出现了Actor-Critic方法结合了值函数和策略梯度,通过两者的互相更新得到更优的结果。
在上述表格中还提及了trajectory distribution 的相关内容,不幸的是我还没有参透这一方面到底是依靠什么来得到策略。或许是轨迹分布,然后看出哪类轨迹得到的奖励多,没有的拟合一下,之后直接使用?【待补充...】
注:

介绍
这两篇文章一共详细介绍了重要性采样、策略约束、不确定性估计和正则化这四类方法,还有 one-step AC 和 multi-step AC 等多个方法。之后就结合我自己读论文的想法和网上的一些资料对这些方法进行梳理和理解。
以下放一张描述 Offline RL 发展很贴切的图片(源自论文Reinforcement Learning in Practice: Opportunities and Challenges)


之后的每一类方法都会分开介绍~ 希望能早日弄懂-_-!
本文摘自 :https://www.cnblogs.com/
