 APP
APP

Elasticsearch 建立在 Apache Lucene 之上,于 2010 年由 Elasticsearch NV(现为 Elastic)首次发布。据 Elastic 网站称,它是一个分布式开源搜索和分析引擎,适用于所有类型的数据,包括文本、数值 、地理空间、结构化和非结构化。Elasticsearch 操作通过 REST API 实现。主要功能是:
- 将文档存储在索引中,
- 使用强大的查询搜索索引以获取这些文档,以及
- 对数据运行分析函数。
Spring Data Elasticsearch 提供了一个简单的接口来在 Elasticsearch 上执行这些操作,作为直接使用 REST API 的替代方法。
在这里,我们将使用 Spring Data Elasticsearch 来演示 Elasticsearch 的索引和搜索功能,并在最后构建一个简单的搜索应用程序,用于在产品库存中搜索产品。
代码示例
本文附有 GitHub 上的工作代码示例。
Elasticsearch 概念
Elasticsearch 概念
了解 Elasticsearch 概念的最简单方法是用数据库进行类比,如下表所示:
| Elasticsearch | -> | 数据库 |
|---|---|---|
| 索引 | -> | 表 |
| 文档 | -> | 行 |
| 文档 | -> | 列 |
我们要搜索或分析的任何数据都作为文档存储在索引中。在 Spring Data 中,我们以 POJO 的形式表示一个文档,并用注解对其进行修饰以定义到 Elasticsearch 文档的映射。
与数据库不同,存储在 Elasticsearch 中的文本首先由各种分析器处理。默认分析器通过常用单词分隔符(如空格和标点符号)拆分文本,并删除常用英语单词。
如果我们存储文本“The sky is blue”,分析器会将其存储为包含“术语”“sky”和“blue”的文档。我们将能够使用“blue sky”、“sky”或“blue”形式的文本搜索此文档,并将匹配程度作为分数。
除了文本之外,Elasticsearch 还可以存储其他类型的数据,称为 Field Type(字段类型),如文档中 mapping-types (映射类型)部分所述。
启动 Elasticsearch 实例
在进一步讨论之前,让我们启动一个 Elasticsearch 实例,我们将使用它来运行我们的示例。有多种运行 Elasticsearch 实例的方法:
- 使用托管服务
- 使用来自 AWS 或 Azure 等云提供商的托管服务
- 通过在虚拟机集群中自己安装 Elasticsearch
- 运行 Docker 镜像
我们将使用来自 Dockerhub 的 Docker 镜像,这对于我们的演示应用程序来说已经足够了。让我们通过运行 Docker run 命令来启动 Elasticsearch 实例:
docker run -p 9200:9200
-e "discovery.type=single-node"
docker.elastic.co/elasticsearch/elasticsearch:7.10.0执行此命令将启动一个 Elasticsearch 实例,侦听端口 9200。我们可以通过点击 URL http://localhost:9200 来验证实例状态,并在浏览器中检查结果输出:
{
"name" : "8c06d897d156",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "Jkx..VyQ",
"version" : {
"number" : "7.10.0",
...
},
"tagline" : "You Know, for Search"
}如果我们的 Elasticsearch 实例启动成功,应该看到上面的输出。
使用 REST API 进行索引和搜索
Elasticsearch 操作通过 REST API 访问。 有两种方法可以将文档添加到索引中:
- 一次添加一个文档,或者
- 批量添加文档。
添加单个文档的 API 接受一个文档作为参数。
对 Elasticsearch 实例的简单 PUT 请求用于存储文档如下所示:
PUT /messages/_doc/1
{
"message": "The Sky is blue today"
}这会将消息 - “The Sky is blue today”存储为“messages”的索引中的文档。
我们可以使用发送到搜索 REST API 的搜索查询来获取此文档:
GET /messages/search
{
"query":
{
"match": {"message": "blue sky"}
}
}这里我们发送一个 match 类型的查询来获取匹配字符串“blue sky”的文档。我们可以通过多种方式指定用于搜索文档的查询。Elasticsearch 提供了一个基于 JSON 的 查询 DSL(Domain Specific Language - 领域特定语言)来定义查询。
对于批量添加,我们需要提供一个包含类似以下代码段的条目的 JSON 文档:
POST /_bulk
{"index":{"_index":"productindex"}}{"_class":"..Product","name":"Corgi Toys .. Car",..."manufacturer":"Hornby"}{"index":{"_index":"productindex"}}{"_class":"..Product","name":"CLASSIC TOY .. BATTERY"...,"manufacturer":"ccf"}使用 Spring Data 进行 Elasticsearch 操作
我们有两种使用 Spring Data 访问 Elasticsearch 的方法,如下所示: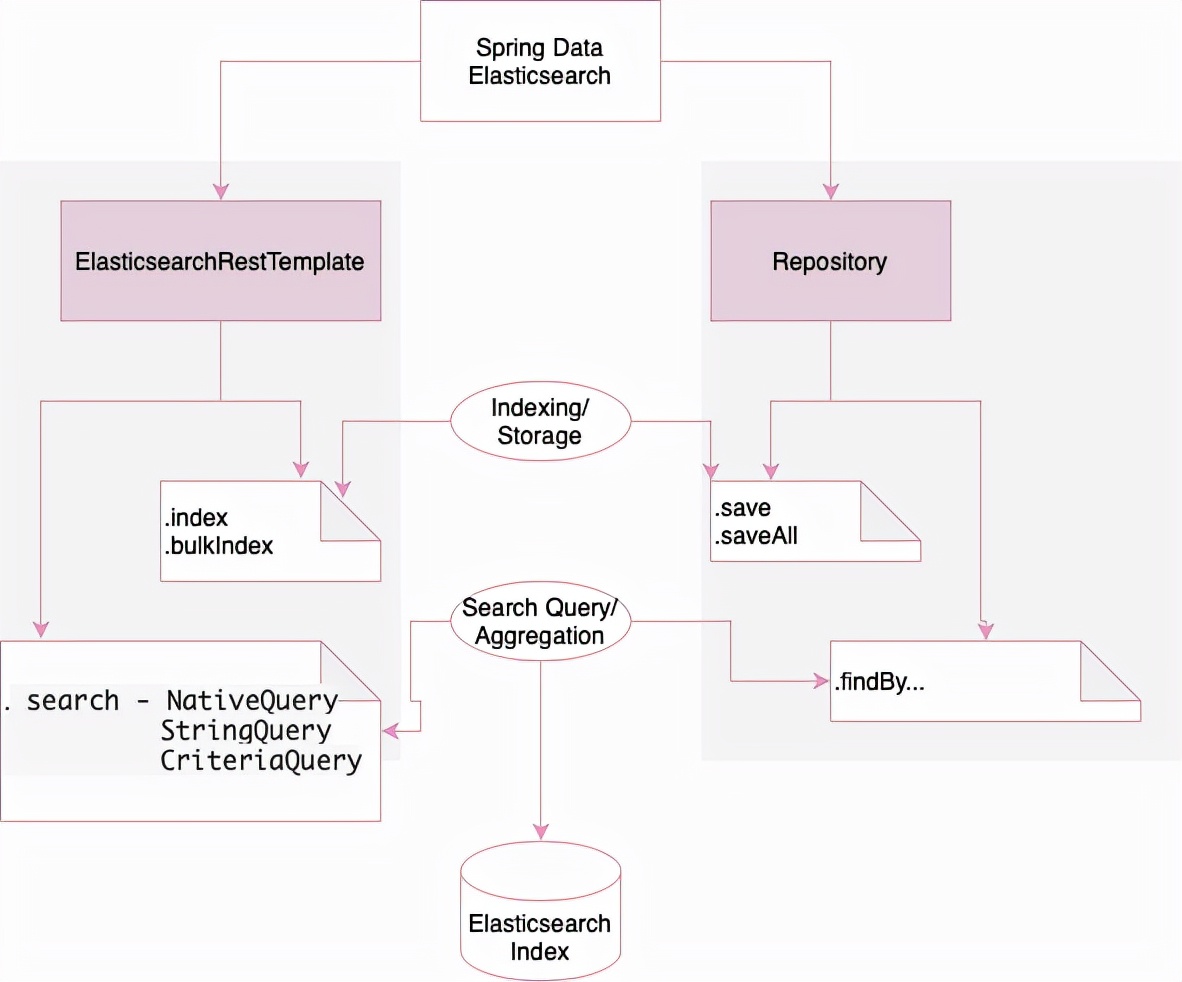
- Repositories:我们在接口中定义方法,Elasticsearch 查询是在运行时根据方法名称生成的。
- ElasticsearchRestTemplate:我们使用方法链和原生查询创建查询,以便在相对复杂的场景中更好地控制创建 Elasticsearch 查询。
我们将在以下各节中更详细地研究这两种方式。
创建应用程序并添加依赖项
让我们首先通过包含 web、thymeleaf 和 lombok 的依赖项,使用 Spring Initializr 创建我们的应用程序。添加 thymeleaf 依赖项以便增加用户界面。
在 Maven pom.xml 中添加 spring-data-elasticsearch 依赖项:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>连接到 Elasticsearch 实例
Spring Data Elasticsearch 使用 Java High Level REST Client (JHLC) 连接到 Elasticsearch 服务器。JHLC 是 Elasticsearch 的默认客户端。我们将创建一个 Spring Bean 配置来进行设置:
@Configuration
@EnableElasticsearch
Repositories(basePackages
= "io.pratik.elasticsearch.repositories")@ComponentScan(basePackages = { "io.pratik.elasticsearch" })
public class ElasticsearchClientConfig extends
AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration =
ClientConfiguration
.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}在这里,我们连接到我们之前启动的 Elasticsearch 实例。我们可以通过添加更多属性(例如启用 ssl、设置超时等)来进一步自定义连接。
为了调试和诊断,我们将在 logback-spring.xml 的日志配置中打开传输级别的请求/响应日志:
public class Product {
@Id
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Double, name = "price")
private Double price;
@Field(type = FieldType.Integer, name = "quantity")
private Integer quantity;
@Field(type = FieldType.Keyword, name = "category")
private String category;
@Field(type = FieldType.Text, name = "desc")
private String description;
@Field(type = FieldType.Keyword, name = "manufacturer")
private String manufacturer;
...
}表达文档
在我们的示例中,我们将按名称、品牌、价格或描述搜索产品。因此,为了将产品作为文档存储在 Elasticsearch 中,我们将产品表示为 POJO,并加上 Field 注解以配置 Elasticsearch 的映射,如下所示:
public class Product {
@Id
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Double, name = "price")
private Double price;
@Field(type = FieldType.Integer, name = "quantity")
private Integer quantity;
@Field(type = FieldType.Keyword, name = "category")
private String category;
@Field(type = FieldType.Text, name = "desc")
private String description;
@Field(type = FieldType.Keyword, name = "manufacturer")
private String manufacturer;
...
}@Document 注解指定索引名称。
@Id 注解使注解字段成为文档的 _id,作为此索引中的唯一标识符。id 字段有 512 个字符的限制。
@Field 注解配置字段的类型。我们还可以将名称设置为不同的字段名称。
在 Elasticsearch 中基于这些注解创建了名为 productindex 的索引。
使用 Spring Data Repository 进行索引和搜索
存储库提供了使用 finder 方法访问 Spring Data 中数据的最方便的方法。Elasticsearch 查询是根据方法名称创建的。但是,我们必须小心避免产生低效的查询并给集群带来高负载。
让我们通过扩展 ElasticsearchRepository 接口来创建一个 Spring Data 存储库接口:
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
}此处 ProductRepository 类继承了 ElasticsearchRepository 接口中包含的 save()、saveAll()、find() 和 findAll() 等方法。
索引
我们现在将通过调用 save() 方法存储一个产品,调用 saveAll() 方法来批量索引,从而在索引中存储一些产品。在此之前,我们将存储库接口放在一个服务类中:
@Service
public class ProductSearchServiceWithRepo {
private ProductRepository productRepository;
public void createProductIndexBulk(final List<Product> products) {
productRepository.saveAll(products);
}
public void createProductIndex(final Product product) {
productRepository.save(product);
}
}当我们从 JUnit 调用这些方法时,我们可以在跟踪日志中看到 REST API 调用索引和批量索引。
搜索
为了满足我们的搜索要求,我们将向存储库接口添加 finder 方法:
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
List<Product> findByName(String name);
List<Product> findByNameContaining(String name);
List<Product> findByManufacturerAndCategory
(String manufacturer, String category);
}在使用 JUnit 运行 findByName() 方法时,我们可以看到在发送到服务器之前在跟踪日志中生成的 Elasticsearch 查询:
TRACE Sending request POST /productindex/_search? ..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"apple","fields":["name^1.0"],..}类似地,通过运行findByManufacturerAndCategory() 方法,我们可以看到使用两个 query_string 参数对应两个字段——“manufacturer”和“category”生成的查询:
TRACE .. Sending request POST /productindex/_search..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"samsung","fields":["manufacturer^1.0"],..}},{"query_string":{"query":"laptop","fields":["category^1.0"],..}}],..}},"version":true}有多种方法命名模式可以生成各种 Elasticsearch 查询。
使用 ElasticsearchRestTemplate进行索引和搜索
当我们需要更多地控制我们设计查询的方式,或者团队已经掌握了 Elasticsearch 语法时,Spring Data 存储库可能就不再适合。
在这种情况下,我们使用 ElasticsearchRestTemplate。它是 Elasticsearch 基于 HTTP 的新客户端,取代以前使用节点到节点二进制协议的 TransportClient。
ElasticsearchRestTemplate 实现了接口 ElasticsearchOperations,该接口负责底层搜索和集群操的繁杂工作。
索引
该接口具有用于添加单个文档的方法 index() 和用于向索引添加多个文档的 bulkIndex() 方法。此处的代码片段显示了如何使用 bulkIndex() 将多个产品添加到索引“productindex”:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<String> createProductIndexBulk
(final List<Product> products) {
List<IndexQuery> queries = products.stream()
.map(product->
new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build())
.collect(Collectors.toList());;
return elasticsearchOperations
.bulkIndex(queries,IndexCoordinates.of(PRODUCT_INDEX));
}
...
}要存储的文档包含在 IndexQuery 对象中。bulkIndex() 方法将 IndexQuery 对象列表和包含在 IndexCoordinates 中的 Index 名称作为输入。当我们执行此方法时,我们会获得批量请求的 REST API 跟踪:
Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex","_id":"383..35"}}{"_class":"..Product","id":"383..35","name":"New Apple..phone",..manufacturer":"apple"}
..
{"_class":"..Product","id":"d7a..34",.."manufacturer":"samsung"}接下来,我们使用 index() 方法添加单个文档:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public String createProductIndex(Product product) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build();
String documentId = elasticsearchOperations
.index(indexQuery, IndexCoordinates.of(PRODUCT_INDEX));
return documentId;
}
}跟踪相应地显示了用于添加单个文档的 REST API PUT 请求。
Sending request PUT /productindex/_doc/59d..987..:
Request body: {"_class":"..Product","id":"59d..87",..,"manufacturer":"dell"}搜索
ElasticsearchRestTemplate 还具有 search() 方法,用于在索引中搜索文档。此搜索操作类似于 Elasticsearch 查询,是通过构造 Query 对象并将其传递给搜索方法来构建的。
Query 对象具有三种变体 - NativeQueryy、StringQuery 和 CriteriaQuery,具体取决于我们如何构造查询。让我们构建一些用于搜索产品的查询。
NativeQuery
NativeQuery 为使用表示 Elasticsearch 构造(如聚合、过滤和排序)的对象构建查询提供了最大的灵活性。这是用于搜索与特定制造商匹配的产品的 NativeQuery:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findProductsByBrand(final String brandName) {
QueryBuilder queryBuilder =
QueryBuilders
.matchQuery("manufacturer", brandName);
Query searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.build();
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
}
}在这里,我们使用 NativeSearchQueryBuilder 构建查询,该查询使用 MatchQueryBuilder 指定包含字段“制造商”的匹配查询。
StringQuery
StringQuery 通过允许将原生 Elasticsearch 查询用作 JSON 字符串来提供完全控制,如下所示:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductName(final String productName) {
Query searchQuery = new StringQuery(
"{"match":{"name":{"query":""+ productName + ""}}}"");
SearchHits<Product> products = elasticsearchOperations.search(
searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
...
}
}在此代码片段中,我们指定了一个简单的 match 查询,用于获取具有作为方法参数发送的特定名称的产品。
CriteriaQuery
使用 CriteriaQuery,我们可以在不了解 Elasticsearch 任何术语的情况下构建查询。查询是使用带有 Criteria 对象的方法链构建的。每个对象指定一些用于搜索文档的标准:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductPrice(final String productPrice) {
Criteria criteria = new Criteria("price")
.greaterThan(10.0)
.lessThan(100.0);
Query searchQuery = new CriteriaQuery(criteria);
SearchHits<Product> products = elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
}
}在此代码片段中,我们使用 CriteriaQuery 形成查询以获取价格大于 10.0 且小于 100.0 的产品。
构建搜索应用程序
我们现在将向我们的应用程序添加一个用户界面,以查看产品搜索的实际效果。用户界面将有一个搜索输入框,用于按名称或描述搜索产品。输入框将具有自动完成功能,以显示基于可用产品的建议列表,如下所示: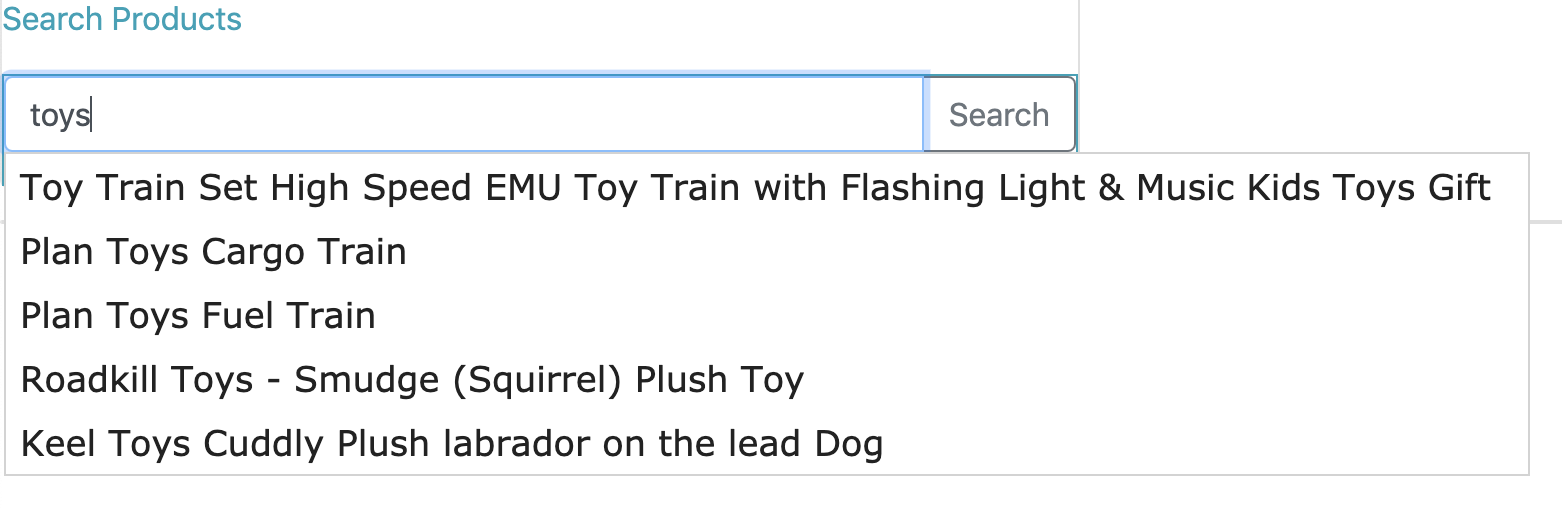
我们将为用户的搜索输入创建自动完成建议。然后根据与用户输入的搜索文本密切匹配的名称或描述搜索产品。我们将构建两个搜索服务来实现这个用例:
- 获取自动完成功能的搜索建议
- 根据用户的搜索查询处理搜索产品的搜索
服务类 ProductSearchService 将包含搜索和获取建议的方法。
GitHub 存储库中提供了带有用户界面的成熟应用程序。
建立产品搜索索引
productindex 与我们之前用于运行 JUnit 测试的索引相同。我们将首先使用 Elasticsearch REST API 删除 productindex,以便在应用程序启动期间使用从我们的 50 个时尚系列产品的示例数据集中加载的产品创建新的 productindex:
curl -X DELETE http://localhost:9200/productindex如果删除操作成功,我们将收到消息 {"acknowledged": true}。
现在,让我们为库存中的产品创建一个索引。我们将使用包含 50 种产品的示例数据集来构建我们的索引。这些产品在 CSV 文件中被排列为单独的行。
每行都有三个属性 - id、name 和 description。我们希望在应用程序启动期间创建索引。请注意,在实际生产环境中,索引创建应该是一个单独的过程。我们将读取 CSV 的每一行并将其添加到产品索引中:
@SpringBootApplication
@Slf4j
public class ProductsearchappApplication {
...
@PostConstruct
public void buildIndex() {
esOps.indexOps(Product.class).refresh();
productRepo.saveAll(prepareDataset());
}
private Collection<Product> prepareDataset() {
Resource resource = new ClassPathResource("fashion-products.csv");
...
return productList;
}
}在这个片段中,我们通过从数据集中读取行并将这些行传递给存储库的 saveAll() 方法以将产品添加到索引中来进行一些预处理。在运行应用程序时,我们可以在应用程序启动中看到以下跟踪日志。
...Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex"}}{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"Hornby 2014 Catalogue","description":"Product Desc..talogue","manufacturer":"Hornby"}{"index":{"_index":"productindex"}}{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"FunkyBuys..","description":"Size Name:Lar..& Smoke","manufacturer":"FunkyBuys"}{"index":{"_index":"productindex"}}.
...使用多字段和模糊搜索搜索产品
下面是我们在方法 processSearch() 中提交搜索请求时如何处理搜索请求:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<Product> processSearch(final String query) {
log.info("Search with query {}", query);
// 1. Create query on multiple fields enabling fuzzy search
QueryBuilder queryBuilder =
QueryBuilders
.multiMatchQuery(query, "name", "description")
.fuzziness(Fuzziness.AUTO);
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.build();
// 2. Execute search
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery, Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
// 3. Map searchHits to product list
List<Product> productMatches = new ArrayList<Product>();
productHits.forEach(searchHit->{
productMatches.add(searchHit.getContent());
});
return productMatches;
}...
}在这里,我们对多个字段执行搜索 - 名称和描述。 我们还附加了 fuzziness() 来搜索紧密匹配的文本以解释拼写错误。
使用通配符搜索获取建议
接下来,我们为搜索文本框构建自动完成功能。 当我们在搜索文本字段中输入内容时,我们将通过使用搜索框中输入的字符执行通配符搜索来获取建议。
我们在 fetchSuggestions() 方法中构建此函数,如下所示:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
public List<String> fetchSuggestions(String query) {
QueryBuilder queryBuilder = QueryBuilders
.wildcardQuery("name", query+"*");
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.withPageable(PageRequest.of(0, 5))
.build();
SearchHits<Product> searchSuggestions =
elasticsearchOperations.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
List<String> suggestions = new ArrayList<String>();
searchSuggestions.getSearchHits().forEach(searchHit->{
suggestions.add(searchHit.getContent().getName());
});
return suggestions;
}
}我们以搜索输入文本的形式使用通配符查询,并附加 * 以便如果我们输入“red”,我们将获得以“red”开头的建议。我们使用 withPageable() 方法将建议的数量限制为 5。可以在此处看到正在运行的应用程序的搜索结果的一些屏幕截图: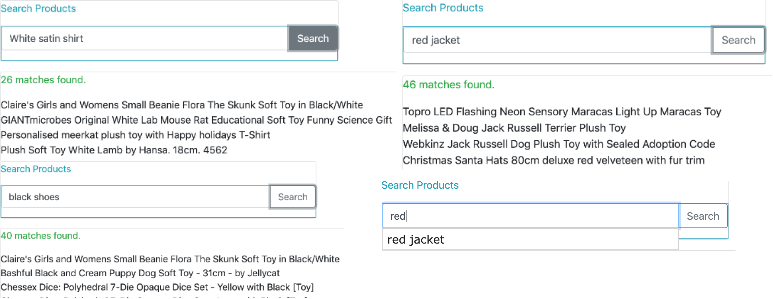
结论
在本文中,我们介绍了 Elasticsearch 的主要操作——索引文档、批量索引和搜索——它们以 REST API 的形式提供。Query DSL 与不同分析器的结合使搜索变得非常强大。
Spring Data Elasticsearch 通过使用 Spring Data Repositories 或 ElasticsearchRestTemplate 提供了方便的接口来访问应用程序中的这些操作。
我们最终构建了一个应用程序,在其中我们看到了如何在接近现实生活的应用程序中使用 Elasticsearch 的批量索引和搜索功能。
- 本文译自: Using Elasticsearch with Spring Boot - Reflectoring
- 有关 ELK 套件请参考: ELK 教程 - 发现、分析和可视化你的数据
本文摘自 :https://blog.51cto.com/c
