 APP
APP
::: hljs-center
1.SQL概述
:::
SQL用来和数据库打交道的,完成和数据库的通信,SQL是一套标准,但是每一个数据库都有自己觉得特性,别的数据库没有,当时用这个数据库特性相关的功能,这是SQL语句可能就不是标准了。
::: hljs-center
2.什么是数据库:
:::
数据库,通常是一个或者一组文件,保存了一些符合特定规格的数据,数据库对应的英语单词是DataBase,简称DB,数据库软件称为数据库管理系统个(DBMS),如Oracle,SQL Server,MySQL,,,,
::: hljs-center
3.mysql概述
:::
Mysql最初是由MySQL AB公司开发的一套关系型数据库管理系统,Mysql不仅是最流行的开源数据库,二期是业界成长最快的数据库,每天有超过7万次的下载量,其应用范围从大型企业到专有的嵌入应用系统
MySQL AB是由两个瑞典人和一个芬兰人在瑞典创办的,从08年初Sun Microsystems收购了MySQL AB公司,在09年Orcle收购了Sun公司,使Mysql并入Oracle的数据库产品线
::: hljs-center
增删改查:crud
:::
C:Create(增)
R:retrive(查:检索)
U:update(改)
D:Delete(删)
::: hljs-center
4.sql语句的分类:
:::
- DQL:数据查询语言(凡是带有select关键字的都是查询语句)
- DML:数据操作语言(凡是对表中数据进行增删改的都是DML)
::: hljs-center
::: hljs-left
insert delete update
:::
:::
insert增
delete删
update改3.DDL:数据定义语言(凡是带有create drop alter都是DDL)DDL主要操作的是结构,不是数据
create :新建 drop:删 alter:改
这个增删改和DML不同,这个主要是对表结果进行操作
4.TCL:事物控制语言(包括事物提交commit,事物回滚:rollback)
5.DCL:数据控制语言(授权grant,撤销权限revoke)
::: hljs-center
5.mysql常用的命令
:::
::: hljs-center
- 登陆命令:mysql -uroot -p 密码
- 查看数据库:show databases;
- 使用数据库:use mysql;
- 查询数据库中的表 :show tables;
- 查看表中的数据:select * from 表名字
- 查看表的结构:desc 表名字
- 查看mysql数据库的版本号:select version();
- 查看当前使用的数据库:select database();
- 终止命令的输入:ctlr +c
- 注意:mysql是不见 “;” 不执行,“;”表示结束!!!
-
:::
::: hljs-center
6.简单查询
:::
1.查询一个字段 :
select 字段名 from 表名
其中要注意:
select 和from都是关键字,都是标识符
对于sql语句都是通用的,都是以‘;’结尾,素有sql语言不区分大小写
2.查询表的结构:
desc 表名;
3.查询一个字段:
select 字段一 from 表名;
4.查询两个或者多个字段,使用逗号隔开
select 字段一,字段二 from 表名;
5.查询所有字段:
5.1.把所有字段都写上
select a,b,c,d,e,f from 表名;
5.2.可以使用
selectl from 表名;6.给查询的列起别名(as关键字)
select 字段1,字段二 as字段二的别名 from 表名;
注意:只是更改了显示结果,原表没改的。select不会进行修改操作的,它只提供查询。
as关键字可以省略,用空格代替
select 字段1,字段二 空格 字段二的别名 from 表名;
假设起别名的时候,别名里面有空格怎么办???
解决方法:
select 字段1,字段二 空格(as) ‘字段二的别名’ from 表名;
如果别名是中文的话,就要用单引号括起来
select 字段一,字段二*12 as ‘中文别名’ from 表名;
7.字段可以使用数学表达式
比如计算字段二的12个月的工资情况。
select 字段一,字段二*12 as 字段二别名 from 表名;
::: hljs-center
7.条件查询where:(筛选)
:::
7.1不是将表中所有的数据都查找出来,是查询出来符合条件的
查询格式:
select
字段1,字段2,字段3
from
表名
where 条件;
7.2条件包括有:
= 等于
查询薪资等于800的姓名和编号
select name,num from 表名 where sal=800;
<> 或者 != 不等于
查询薪资不等于800的姓名和编号
select name,num from 表名 where sal!=800;
select name,num from 表名 where sal<>800;
< 小于
查询薪资小于2000的员工姓名和编号
select name.num from 表名 where sal < 2000;
<=小于等于
查询薪资小于等于2000的员工姓名和编号
select name,num from 表名 where sal <= 3000;
**> 大于
=大于等于
同理;**
between and 介于两者之间
查询薪资在2450到3000之间的员工信息,包括2450和3000
**第一种方法:>= and <=**
select
name,num
from
表名
where
sal >= 2450 and sal <= 3000 ;**第二种方法:between and**
select
name,num
from
表名
where
sal between 2450 and 3000 ;查询哪些员工的津贴补助为null
is null 为null
is not null 不为null
select name,num from 表名 where comm is null;在数据库中,null不能使用=进行衡量,需要使用is null,null代表什么也没有,不是一个值,所以不能使用等号。
查询哪些员工的津贴补助不为null
select name,num from 表名 where comm is not null;
查询工作岗位为MANAGER并且工资大于2500的员工信息
and 并且
select name,num from 表名 where job='MANAGER' and sal > 2500;
or 或者
查询工作岗位是manage和工作岗位是SALESMAN的员工
select name,num,job from 表名 where job = 'manage' or job = 'SALESMAN';
in 包含,相当于多个or
查询工作岗位是manage和salesman的员工
select name,num,job from 表名 where job in ('manage','saleman');
eg:查询薪资是800和5000的员工信息
select name,num,sal from 表名 where sal = 800 or sal = 5000;
select name,num,sal from 表名 where sal in (800,5000);not in 不在这几个值中的数据
select name,num,sal from 表名 where sal not in (800,3000,5000);
like 称为模糊查询,支持%或者下划线匹配
%:匹配任意多个字符
下划线:一个下划线只匹配一个字符
eg:找出名字中含有字母O 的
select name from 表名 where name like '%O%';
2.找出名字以T 结尾的
select name from 表名 where name like '%T';
找出第二个字母是A 的
select name from 表名 where name like '_A%';
找出以k开头的名字
select name from 表名 where name like ‘K%’;
找出第三个字母是R的名字
select name from 表名 where name like '__R%';
找出名字中有‘_’的 (转义字符)
select name form 表名 where name like '%_%';
::: hljs-center
7排序数据
:::
单一字段排序
排序采用order by 子句,order by后面跟上排序的字段,排序字段可以放多个,多个采用逗号分隔,order by默认采用升序,如果存在where子句,那么order by 必须到where语句的后面
按照薪水由小到大排序(系统默认是由小到大)
查询所有员工薪资排序
select name.num.sal from 表名 order by sal;
降序
select name.num.sal from 表名 order by sal desc;
两个或者两个以上的字段排序
薪资一样的话,就安装员工的姓名排序(升序)
select
name,num
from
表名
order by
sal asc,name asc;sal在前,起主导,只有sal相等的时候,才会考虑name.
根据字段的位置可以进行排序
按照查询结果的第二列sal进行排序。
select name.num,sal from 表名 order by 2;
eg:找出工资在1250到3000之间的员工信息,要求按照薪资降序排列
select name,num,sal from 表名 where sal between 1250 and 3000 order by sal desc;
::: hljs-center
8.数据处理函数
:::
数据处理函数又被称为单行处理函数,
单行处理函数:一个输入对应一个输出
多行处理函数:多个输入对于一个输出
单行处理函数常见的有:
::: hljs-center
- Lower 转换小写
- upper 转换大写
- substr取子串(截取的字符串,起始下标,截取的长度)注意:起始下标从1开始
- concat 字符串拼接
- length 取长度
- trim 去空格
- str_to date 将字符串转换成日期
- date_format 格式化日期
- format 设置千分位
- round 四舍五入
- rand() 生成随机数
- Ifnull 可以将null转换成一个具体值
- case..when..than..when..then..else..end 当什么时候怎么做,其他时候怎么做。
:::
eg:lower例子
select lower(name) from 表名;
eg:upper例子
select upper(name) from 表名;
eg:找出员工名字第一个字母是A的员工信息
第一种方式:
select name,num from 表名 where name like 'A%';
第二种方式:
select name,num from 表名 where substr(name,1,1) = 'A';eg:concat字符串拼接
select concat(name,num) from 表名;
eg:length取字符串长度
select length(name) as namelength from 表名;
eg:trim 去空格
select * from 表名 where name = trim (' hahahah');
eg:round 四舍五入保留整数位: select round(1234.56,0) from 表名; 保留一位小数: select round(1234.56,1) from 表名; 精确到十分位: select round(1234.56,-1) from 表名;
eg:生成随机数
select rand() from 表名;
100以内的随机数:select round(rand()*100,0) from 表名;

ifnull 是空处理函数,在所有数据库当只当中,只要有null参与的运算,最终结果都是null;**
select name, sal+comm from 表名;**
*select name,(sal+comm)12 from 表名; 这是错误的做法
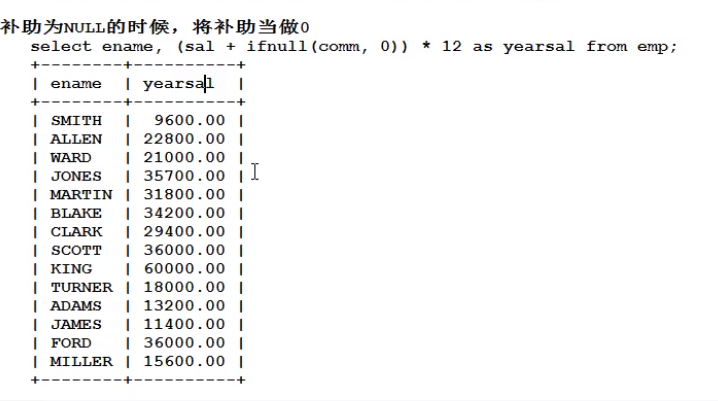
ifnull(数据,被当做哪个值),当补助为null的时候,把补助当做0 来计算。**
select name,(sal+ifnull(comm,0))*12 from 表名;
eg:当员工的工作岗位是manage的时候,工资上涨10%,当工作岗位是salesman的时候,公司上调50%
select name,job,sal as oldsal(case job when 'manage' than sal81.1 when 'saleman' than sal*1.5 else sal end) as newsal from 表名;

::: hljs-center
9.分组函数(多行处理函数)
:::
多行处理函数的特点:输入多行,最终输出一行
::: hljs-center
#### 5个分组函数
- count 计数
- sun 求和
- max 最大值
- min 最小值
- avg 平均值
:::
eg:计算出最高工资
select max(sal) from 表名;
eg:计算出最低工资
select min(sal) from 表名;
eg:计算出员工的全体总工资
select sum(sal) from 表名;
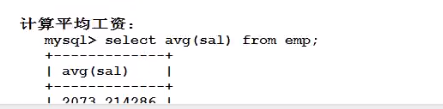
eg:计算出全体员工的平均工资:
select avg(sal) from 表名;
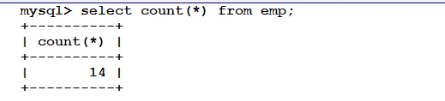
eg:计算出这家公司有多少人
select count(name) from 表名;
分组函数在使用的时候需要注意哪些?
注意事项1.分组函数自动忽略null
*2注意事项二.eg:count()和count()的区别是什么?*
select coutn() from 表名;selet count(comm) from 表名;
count(*):表示统计表中的总行数,(只要有一行数据,count++)
count(comm) :表示统计该字段下所有部位NULL的元素的总数。






注意事项三:所有的分组函数可以组合起来一起用
select sum(sal),min(sal),max(sal),avg(sal),count(*) from 表名;
::: hljs-center

10.分组查询
:::
分组查询:在实际的应用各种,可能哟这样的需求,先进行分组,对每一组的数据进行操作,这个时候,我们需要分组查询,如何来分组查询呢?
select …… from …… group by ……
将之前的关键字全部组合在一起,看一下他们的执行顺序
select
……
from
……
where
……
group by
……
order by
……执行顺序是
from------where-------group by -------select----order by
注意事项四:分组函数不能直接使用在where字句中
eg:找出比最低工资高的员工信息
select name,num from 表名 where sal > min(sal);
- 这是错误滴,会报错,为什么呢???
- 因为where在group by分组函数之前!!!!
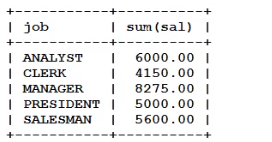
列如:找出每个工作岗位的工资和
select job,sum(sal) from 表名 group by job;
- 语句的执行顺序:先从表总查询数据
- 2.根据job字段进行分组
- 3.然后对每一组的数据进行sum(sal)
重点结论:在一条select语句当中,如果有group by语句的话,select后面只能跟参加分组的字段,以及分组函数之外,其他的一律都不要加!!!!
例如1:找出每个部门的最高薪资
select 部门编号,max(sal) from 表名 group by 部门编号;

例题2:找出每个部门,不同工作岗位的最高薪资
select 工作岗位,部门, max(sal) from 表名 group by 部门,工作岗位;

例题三:使用having可以对分完组之后的数据进一步过滤,having必须和group by联合使用,
找出每个部门的最高薪资,要求显示最高薪资大于3000?
select 部门,max(sal) from 表名 group by 部门 having max(sal) > 3000;
方法二:先筛选出>3000过滤掉,然后在分组,在进行查询。
select 部门,max(sal) from 表名 where sal> 3000 group by 部门;
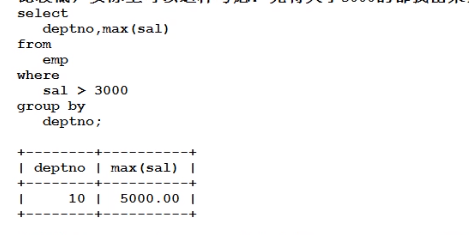
例题四:where没有办法的
找出每个部门的平均薪资,要求显示平均薪资高于2500的
select 部门 avg(sal) from 表格 group by 部门 having avg (sal)>2500;
select 部门 avg(sal) from 表格 where avg(sal)>2500 group by 部门 ;
这是错误的,因为因为,分组是在where之后执行的,而avg(sal)是分组函数。所以在这里只能使用having。
例题五:找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除开manage之外,要求按照平均薪资降序排序
select 岗位,avg(sal) from 表名 where job != 'manage' group by 岗位 having avg(sal) > 1500 order by avg(sal) desc;

把查询结果去除重复记录(distinct)
select job from 表名
select distinct job from 表名


distinct出现在两个字段之前,表示,这两个字段联合起来去重。
select distinct job,deptno from 表名;
例如:统计一下工作岗位的数量?
select count(dostomct job) from 表名

::: hljs-center
11.连接查询
:::
连接查询的概念:
从一张表中淡出查询,称为单标查询
多张表联合起来查询数据,被称为连接查询。连接查询的分类:
1.根据语法的年代分类:
SQL92:1992年出现的语法
SQL99:1999年出现的语法2.根据表连接查询的方式分类:
内连接:
- 等值连接
- 非等值连接
- 自连接
外连接:- 左外连接:
- 右外连接:
全连接注意:当两张表进行连接查询的时候,没有任何条件的限制会发生什么现象???
笛卡尔积现象,它是一个数学现象。
避免笛卡尔积现象!!!
连接时加条件,满足这个条件的记录筛选出来,但是匹配次数是没有减少的,只不过把条件符合的筛选出来select name,num from 表一,表二 where 表一.编号 = 表二.编号;

提高效率,可以给表起别名

我们来看一下92语法和99语法的语法格式
比如,显示员工属于哪个部门,并且显示出员工和部门信息
SQL92
select
表一别名.姓名,表二别名.部门
from 表一 别名 ,表二 别名
where
表一别名.部门编号 = 表二别名.部门编号;
SQL99
select
表一别名.姓名,表二别名.部门
from
表一 别名 join 表二 别名
on
表一别名.部门编号 = 表二别名.部门编号;
……
where 筛选条件以上可以看出,sql92的缺点,结果不清晰,表的连接条件,和后期进一步筛选的条件都放到where中
sql99的优点:表连接的条件是独立的,连接之后,如果还需要进一步筛选,可以在语句后面加where,
内连接之等值连接(inner)
select
e.ename,d,dname
from
emp e
inner join
emp b
on
e.deptno = d.deptno;内连接之非等值连接
条件不是一个等量关系,称为非等值连接。
eg:找出每个员工的薪资等级,要求显示员工名,薪资,薪资等级。
select
a.ename,a,sal,s.grade
from
emp a
inner join
salgrade s
on
a.sal between s.losal and s.hisal;内连接之自连接
eg:查询员工的上级领导,要求显示员工名和对应的领导名
技巧:一张表看成两张表,
select
a.ename as ‘员工名’,b.ename '领导名'
from
emp a
join
emp b
on a.mgr = b.empno;外连接
外连接(右外连接right)
select
e.ename, d.dname
from
emp e right join dept d
on
e.deptno = d.deptno;外连接(左外连接 left)
select
e.name , d.name
from
dept d left join emp e
on
e.deptno = d.deptno;right 代表join关键字右边的这张表看成主表,主要是为了将这张表的数据全部查询出来,捎带着关联查询左边的表,在外连接当中个,两张表连接,产生了主次关系
带有right的是右连接,
带有left的是左连接
任何一个右或者左连接都有他们左或者右的写法。
//outer 可以省略select e.name , d.name from dept d left outer join emp e on e.deptno = d.deptno;
**eg:查询每个员工的上级领导,要求显示所有员工的名字和领导名。**
select
a.ename,b.ename
from
emp a left join emp b
on
a.mgr = b.empno;

#### 多张表怎么连接select
……
from
a
join
b
on
a和b的条件
join
c
on
a和c的条件
right join
d
on
a和d的条件
**一条sal语句中,内连接和外连接都能够混合使用,**
> eg:找出每个员工的部门名称,以及工资等级,要求显示员工名 工资 部门名 薪资等级select
e.ename,e.sal,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno = d.deptno;
join
salgrade s
on
e.sal between s.losal and s.hisal;
::: hljs-center
## 12.子查询
:::
#### 什么是子查询:
> select 语句中嵌套了select语句,被嵌套的select语句称为子查询
#### 子查询都可以出现在哪里呢?select
……(select)
from
……(select)
where
……(select)
……
#### where字句中的子查询
> eg:找出比最低公司高的员工姓名和工资select
ename,sal
from
emp
where
sal>(select min(sal) from emp);
#### from字句中的子查询
**from后面的子查询,可以把子查询中的结果当做一张临时表。**
eg:找出每个岗位的平均工资的薪资等级
> 每个岗位的平均工资:
select job,avga(sal) from emp group by job;
等级:select
t.*,s.grand
from
(select job,avga(sal) as sal from emp group by job) t
join
salgrade s
on
t.sal between s.losal and s.hisal;
#### select出现的子查询
eg:找出每个员工的部门名称,要求显示员工名和部门名??
select
e.name e.deptno,
(select d.dname from dept d where
e.deptno = d.deptno) as dname
from emp e;

## union合并查询结果
> eg:查询工作岗位是manage和saleman的员工select
ename,jog
from
emp
where
job='manage'or job='saleman';
union的使用
select ename,job from emp where job = 'manage';
union
select ename,job from emp where job = 'saleman';
union的优点:
> union的效率高一些,对于表连接来说,每连接一次新表,则匹配的次数满足笛卡尔积,但是union可以减少匹配的次数,在减少匹配次数的情况下,还可以完成两个结果的拼接
**注:union使用的注意事项:
union在进行结果集合并的时候,要求结果集的列数要想同!!!**select ename from emp where job = 'manage';
union
select ename,job from emp where job = 'saleman';
**这样就是错误的**
::: hljs-center
## 14.limit分页查询
:::
> limit:显示结果集的一部分数据。
分页的作用:提高用户的体验,因为一次全部都查出来,用户体验差,可以翻页查看。
limit的使用:
eg:安装薪资降序,取出排序在前五名的员工select
ename,sal
from
emp
order by
sal desc
limit 5;
**完整写法:**
limit的用法,后面可以跟两个数字,
limit startIndex (起始下标,从0开始), length(长度);
**缺省用法:**
limit 5;取前五
**在myql中,limit在order by之后执行。**
eg:取出工资排名在3-5名的员工select
ename,sal
from
emp
order by
sal desc
limit 2,3;
> eg:取出工资5-9名的员工select
ename,sal
from
emp
order by
sal desc
limit 4,5;
## 分页
**每页显示3条记录**
第一页:limit 0,3
第二页:limit 3,3
第三页:limit 6,3
第四页:limit 9,3
每页显示pagesize条记录,第pagenum页:
limit (页码-1)*pagesize,pagesize;
关于DQL语句总结:select
……
from
……
where
……
group by
……
having
……
order by
……
limit
> 执行顺序:
from --- where---- group by ----having---- select---- order by ----limit
::: hljs-center
## 15.表的创建
:::
#### 1.建表的语法格式(DDL)
create table 表名 (
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型);
> 表名:建议以t_或者tbl_开始,可读性强,见名知意。
#### 2.数据类型有:
> varchar:可变长度的字符串,会根据实际的数据长度动态分配空间。
> char:定长字符串,不管实际数据长度,分配固定长度的空间去存储数据。使用不恰当,可能会导致空间的浪费。int:数字中的整型,最长(11位)
bigint:数字中的长整型
float:单精度
double:双精度
date:短日期类型
datetime:长日期
clob:字符大对象,最多可以存储4G的字符串(255位)
比如:文章,说明,简介
blob:二进制大对象,专门用来存储图片,声音,视频,等流媒体数据。往BLOB类型字段上插入数据的时候,需要使用IO流
**
eg:创建一个学生表**
学号、姓名、性别、年龄、邮件地址
create table t_student (
num int,
name varchar(20),
sex char(1),
age int(3)
e-mail varchar(255));
**删除表** drop table t_student; //当这张表不存在的时候会报错
drop table if exists t_student ; //当这张表存在的时候删除

#### 4.插入数据:insert(DML)
语法格式
insert into 表名 (字段名1,字段名2,字段名3,……) values(值1,值2,值3,……);
注意:字段名和值要一一对应,数据类型要对应,
eg:mysql> insert into t_student (no,name,age,sex,email) values (1,'张三',20,'m','zhangsan@qq.com');

**注意:前民的字段可以省略,后面的值必须要一一对应写上,!!**
#### 5.格式化数字:format(数字,‘格式’)
#### str_to_date 将字符串转换为日期类型
> 语法格式:str_to_date(‘字符串日期’,‘日期格式’)
> mysql的日期格式有:%Y/%m/%d/%h/%i/%s

#### date format 将日期类型转换成特定格式
**date format(日期类型数据,‘日期格式’)**
> 它会自动将数据库中的date类型转换成varchar类型,并且采用的格式是mysql的默认的日期格式。

#### date和datetime两个类型的区别
> date:是短日期,只包括年月日信息
datetime长日期,包括年月日时分秒信息

#### now()获取系统当前时间

## 修改update(DML)
语法格式:
> update 表名 set 字段名1=值1字段名2=值2,字段名3=值三,…… where 条件;
注意:如果不加where条件,会导致所有的数据全部更新!!!!

## 删除数据delete(DML)
delect from 表名 where 条件
注意:没有条件,整张表的数据都会删除。
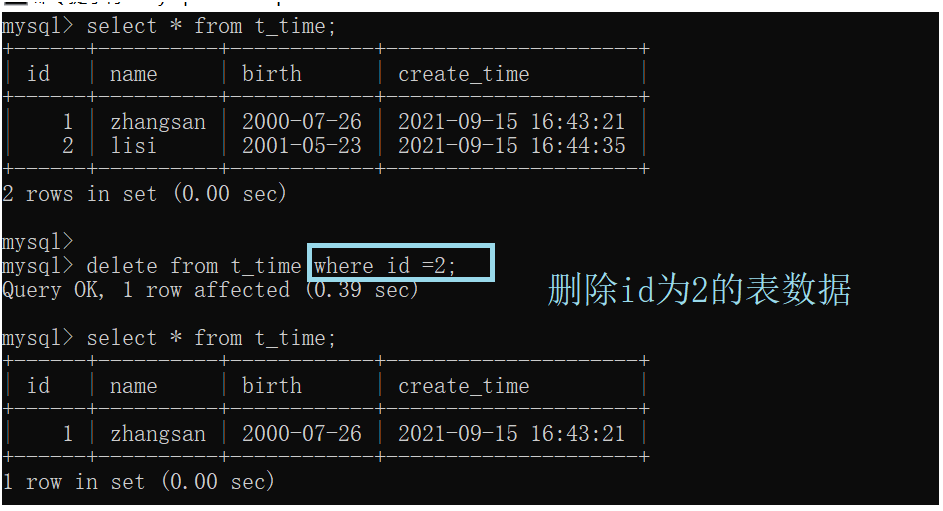

**注意:delete删除之后可以回滚数据,可以恢复数据,数据在硬盘上的真实存储空间不会被释放,缺点是:删除效率比较低,**
**truncate:语句删除效率比较高,表被一次性清理了,不能恢复。
**
> truncate table表名;

#### insert可以一次性插入多条记录
语法格式:
> insert into t_time (字段名1,字段名2,字段名3) values(值1,值二,值三),(值1,值二,值三);

#### 快速创建表
语法格式
**create table 表名 as select * from 表二;**
> 原理:将一个查询结果当做一张表新建
这个可以完成表的快速复制
表创建出来,同时表中的数据也存在了

#### 表结构的增删改
alter(修改)
create(创建)
drop(删除)
> 1.在实际的开发中,需求一旦确定设计好之后,很少进行表结构的修改,添加字段,删除字段,修改字段等等。
因为开发进行中,修改表结构成本比较高,
::: hljs-center
## 16.约束
:::
约束:约束字段
#### 什么是约束????
> 约束(constraint),在创建表的时候,给表中的字段加一些约束,来保证表中数据的完整性和有效性。
#### 约束包括有:
> 非空约束:not null
唯一性约束:unique
主键约束:primary key
外键约束:foreign key
检查约束:check
#### 1.非空约束:not null;
它约束的字段不能为null;

#### 2.唯一性约束(unique)
> 唯一性约束unique约束的字段不能重复,但是可以为空



#### 表级约束
> 什么时候使用表级约束呢?
需要给多个字段联合起来添加某一个约束的时候,需要使用表级约束,not null 没有表级约束语法,unique有。



#### unique和not null 联用
在mysql中,如果一个字段同时被not null和unique同时约束的时候,该字段自动称为主键字段。

#### 主键约束
#### 1.主键约束的相关术语
> 主键约束、主键字段、主键值
主键约束:就是一种约束
主键字段该字段上添加了主键约束,这样的字段叫做:主键字段
主键值:主键字段中的每一个值叫做主键值
#### 2.什么是主键,有什么用??
> 主键值是每一行记录的唯一标识
主键值是每一行记录的身份证号
注意:任何一张表都应该有逐渐,没有主键,表无效!!!!
主键的特征:not null + unique(主键值不能是null,也不能重复,要具有唯一性)相当于身份证号。
**如何给一张表添加主键约束**
列级约束:

表级约束:

多个字段联合起来添加一个主键约束,

####
外键约束
外键约束可以为NULL,外键约束引用的字段不一定是主键,但是至少具有unique约束。

::: hljs-center
## 17.存储引擎
:::
**什么存储引擎???**
> 指定不同的存储引擎,表的存储结构不一样。
如何给表指定存储引擎
**show create table t_student;**
在建表的时候可以在最后小括号的右边使用:

> ENGINE:来指定存储引擎
CHARSET:来指定这张表的字符编码方式
默认的存储引擎是InnoDB
默认的字符编码是UTF-8;

#### 查看mysql中支持得存储引擎
**mysql> show engines G**
::: hljs-center
## 18.事物
:::
> 一个事物其实就是一个完整的业务逻辑。只有dml语句才会哟事物有关,其他语句都和事物无!!!!
因为只有update insert delete 这三个语句是对数据表中的数据进行增删改的,只要是涉及到数据的增删改的那么久一定要考虑到安全问题,数据安全是第一位。
#### 什么是事务呢?
> 一个事物就是多条dml语句同时成功或者同时失败。
#### 事务是怎么做到多条dml语句同时成功和同时失败的呢?
> innoDB存储引擎:提供一组哟哪里记录事务性活动的日志文件。
在事务的执行过程中,每一条dml的操作都会记录到事务性活动的日志文件中,在事务的执行过程中,我们可以提交事务,也可以回滚事务。
提交事务:清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中,提交事务标志着,事务的结束,并且是一种全部成功的结束
回滚事务:将之前所有的dml操作全部撤销,并且清空事务性活动的日志文件,回滚事务标志着,事务的结束,并且是一种全部失败的结束
#### 事务的4个特性:
> 原子性:说明事务是最小的工作单元,不可再分
一致性:所有事务要求,在同一个事务当中,多有操作必须同时成功,或者同时失败,
隔离性:A事务和B事物之间具有一定的隔离,像教室一样,教室的那道墙就是隔离性,
持久性:事物最终结束的一个保障,事物提交,就相当于将没有保存到硬盘上的数据保存到硬盘上。
#### 事物的隔离性:
**1.读未提交:read uncommitted(最低的隔离级别)(没有提交就已经读到了)**
什么是读未提交:
事物A可以读取到事物B未提交的数据
这种隔离级别存在的问题就是:
脏读现象:(Dirty Read)
我们称为读到了脏数据,这种隔离级别一般都是理论上的,大多数的数据库隔离级别都是二挡起步!!!
#### 2. 读已提交:read committed(提交之后才能读到)
**什么是读已提交:**
事物A只能读取到事物B已经提交了的数据
**这种隔离级别解决了什么问题?**
解决了脏读现象
**这种隔离级别存在什么问题?**
不可重复读取数据
**什么是不可重复读取数据呢?**
在事务开启之后,第一次读到的数据是3条,当前事务还没有结束,可能第二次在读取的时候,读到的数据是4条,4不等于3,称为不可重复读取,
> 这种隔离级别是比较真实的数据,每一次读到的数据是绝对的真实,oracle默认数据库的隔离级别是:read committed
#### 3.可重复读(提交之后也读不到,永远读取的都是刚开始事务)
**什么是可重复读取??**
事务A开启之后,不管是多久,每一次在事务A中读取到的数据都是一致的,即使事务B将数据已经修改,并且提交了,事务A中
读取到的数据还是没有发生改变,这就是可重复读。
**可重复读解决了什么问题?**
解决了不可重复读取数据
**可重复读存在的问题是什么?**
可能会出现幻影读
**每一次读取到的数据都是幻象,不够真实,**
#### 4.序列化/串行化:selializable(最高的隔离级别)
> 这是最高隔离级别,效率最低,解决了所有的问题,这种隔离级别表示事务排队,不能并发,每一次读取到的 **数据都是最真实的,并且效率是最低的**
**eg:使用read uncommitted 读未提交**




::: hljs-center
## 19.索引
:::
#### 什么是索引:
> 索引在数据库表的字段上添加,为了提高检索查询效率存在的一种机制
,一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引,索引相当于一本书的目录,是为了缩小扫描范围而存在的机制。
#### 对于一本字典来说,查找某个汉子有两种方式:
> 1.一页一页挨着找,知道找到位置,这种查找方式属于字典扫描
2.第二种方式,先通过目录去定位一个大概的位置,然后直接定位到这个位置,做局域性扫描,缩小扫描的范围,快速的插座,这种查找方式属于通过索引检索,效率较高。

> 如果name字段上没有没有添加索引,或者说没有给name字段创建索引,mysql会进行全扫描,会将name字段上的每一个值都比对一遍,效率比较低,
**mysql在查询方面主要就是两种方式:1.全表扫描,2.添加索引(缩小扫描范围)。**
遵循左小右大原则存放,采用中序遍历取数据
我们来看索引的实现原理把!!!!

在mysql中,索引是一个单独的对象,不同的存储引擎以不同的形式存在,在myisam存储引擎中,索引存储在一个myi文件中,在innoDB存储引擎中索引存储在一个逻辑名称叫做tablespace当中,在memory存储引擎中索引被存储在内存当中,不管索引存储在哪里,索引在mysql当中都是一个树的形式存在(自平衡二叉树:B-Tree).


#### 在mysql当中,主键上,以及unique字段上都会自动添加索引
**什么条件下,我们会考虑给字段添加索引???**
> 条件1:数据量庞大
条件二:该字段经常出现在where后面,以条件的形式存在,这个字段经常被扫描
条件三:该字段很少dml操作,因为dml之后,索引需要重新排序。
#### 索引的创建 删除 查看
创建索引:




#### 索引失效
第一种情况

第二种情况

第三种情况

第四种情况

第五种情况:

#### 索引在数据库中的分类:
> 单一索引:一个字段上添加索引
复合索引:两个字段或者更多的字段上添加索引
主键索引:主键上添加索引
唯一性索引:具有unique约束的字段上添加索引。
越唯一,效率越高!!!!
::: hljs-center
## 20.视图
:::
#### 1.什么是视图:
> view:站在不同的角度去看待同一份数据,视图是用来简化sql语句的。
#### 2.创建视图:
create view 视图名字 as select * from emp;
mysql> create view dept_view as select * from dept2;
Query OK, 0 rows affected (0.01 sec)
#### 3.删除视图:
drop view 视图名mysql> drop view dept_view;
Query OK, 0 rows affected (0.03 sec)
注意:视图as后面必须是DQL语句
#### 4.用视图做什么???
> 我们对视图对象进行增删改查,会导致原表被操作,

视图更新
**mysql> update dept_view set dname = 'xiejaingmei' where deptno = 60;**

假设有一条非常复杂的sql语句,而这条sql语句需要在不同的位置上反复使用,每一次使用这个sql语句的时候都需要重新编写,很长,很麻烦,怎么办,可以把这条复杂的sql语句以视图对象的形式新建。

::: hljs-center
## 21.DBA常用命令
:::
数据备份
#### 数据导出:在cmd命令行执行:
> mysqldump 库名 >D:位置.sql -uroot -p密码;
mysqldump 库名 表名 >D:位置.sql -uroot -p密码;

#### 数据导入:
> 进入数据库
mysql -u root -p 密码
创建库
create database xjm;
使用数据库
use xjm;
初始化数据库
source D:xjm.sal;
::: hljs-center
## 22.数据库设计的三范式
:::
数据库表的设计依据,教你怎么进行数据库表的设计
> 第一范式:
要求一张表必须有主键,没一个字段原子性不可再分
第二范式:
建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
第三范式:完全建立在第二范式基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
按照以上的范式进行,可以避免表中数据的冗余,避免空间的浪费
**第一范式:最核心,最重要的范式,所有表都需要满足,必须要有主键,并且每一个字段都是原子性不可再分。**

第二范式,建立在第一范式基础之上,要求所有非主键字段,完全依赖于主键,不要产生部分依赖



第三范式,建立在第二范式的基础上,要求所有非主键字段完全依赖主键,不要产生传递依赖


一个班级对应多个学生
## 多对多:三张表,关系表,两个外键
一对多:二张表 多的表加外键
一对一:在实际开发中,可能存在一张表字段太多,太庞大,这个时候要拆分表。
#### 总结表的设计
> 一对一:外键唯一(fk+unique)
一对多:二张表 多的表加外键
多对多:三张表,关系表,两个外键本文摘自 :https://blog.51cto.com/u
