 APP
APP
BF算法
bf算法(brute force)顾名思义,是很暴力,很朴素的算法,我们把想要匹配的字符串叫做模式串,通俗理解来说就是模板,把被进行搜索来查找有无匹配的子串的字符串叫做主串,比如用户输入的字符串。
bf算法是这样的:假设主串长度为n,模式串的长度对我们从主串的初始位置0开始,每次查找长度为m的字符串,直到找到匹配的字符串或者最多查找了n - m + 1次结束。
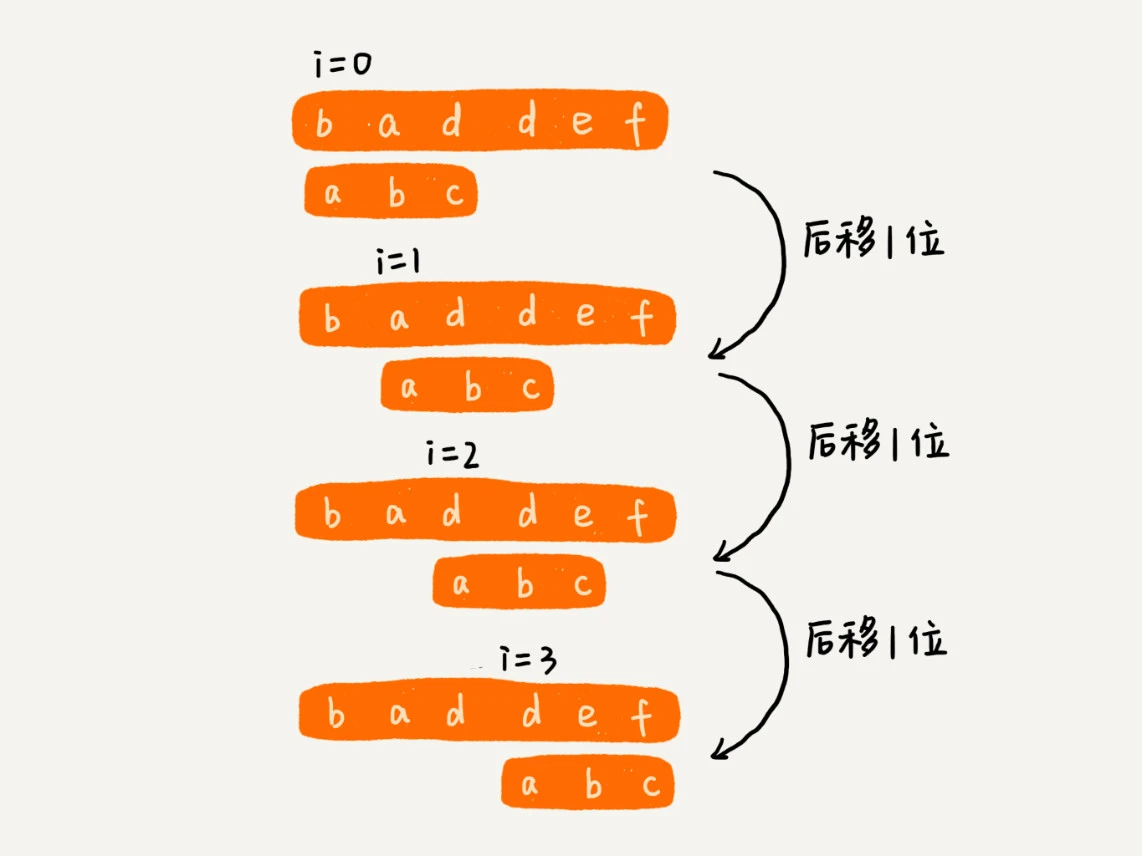
为什么说最多只会查找n - m + 1呢?从图中就能看出来了,当比较到了n - m次时,这时主串中还没有被比较过的字符就只剩下m个了,你顶多只能再比较一次,所以最多只能是n - m + 1次。
bf算法在极端情况下,比如,主串是一大串a,而子串是aaab,那么每次比较m个字符,比较n - m + 1次,会有时间复杂度O(n * m),这看起来很高,但是事实上,我们可以每次比较时一旦遇到不匹配的字符就停下当次比较,而且实际开发遇到的主串和模式串一般不会很长,所以其实大部分情况下,执行效率都会比这个O(n * m)高很多,并且bf算法暴力朴素,不容易出错,即便有出错也更容易排查出来,在工程中,满足性能的情况下,简单是首选,这也是KISS设计原则(keep it simple and stupid)所以,bf算法还是很常用的。
RK算法(Rabin - Karp)
rk算法以它的两位发明者进行命名,该算法其实是在暴力匹配算法的基础上配合哈希算法使用。
为什么要配合上哈希算法使用呢,这是因为暴力匹配算法时间复杂度并不是很低,所以我们将主串的每个子串先转为哈希值(注意要考虑哈希值冲突,但我们这个例子中的哈希算法,对于不同字符串,哈希值是不同的,没有冲突),然后把模式串的哈希值与各个子串比较,如果相等,就证明匹配成功。并且由于哈希值是数字,所以比较会很迅速。

当然啦,这样的话匹配算法的复杂度不仅受哈希值比较影响,还会受哈希函数把字符串转化为哈希值的计算速度的影响,所以我们还要选择合适的哈希函数。
假设我们要操作的字符串集含有K个字符,那么我们可以用K进制来代替字符串。
比如我们可以假设我们操作的字符集只含有a~z26个字母,那么我们就可以用26进制,a对应1,b对应2.....这样对应下去,这时由于进制达到了两位数,所以将子串转化成十进制数,这个十进制数来当哈希值就可以了。转化的方式还是“乘权求和”。
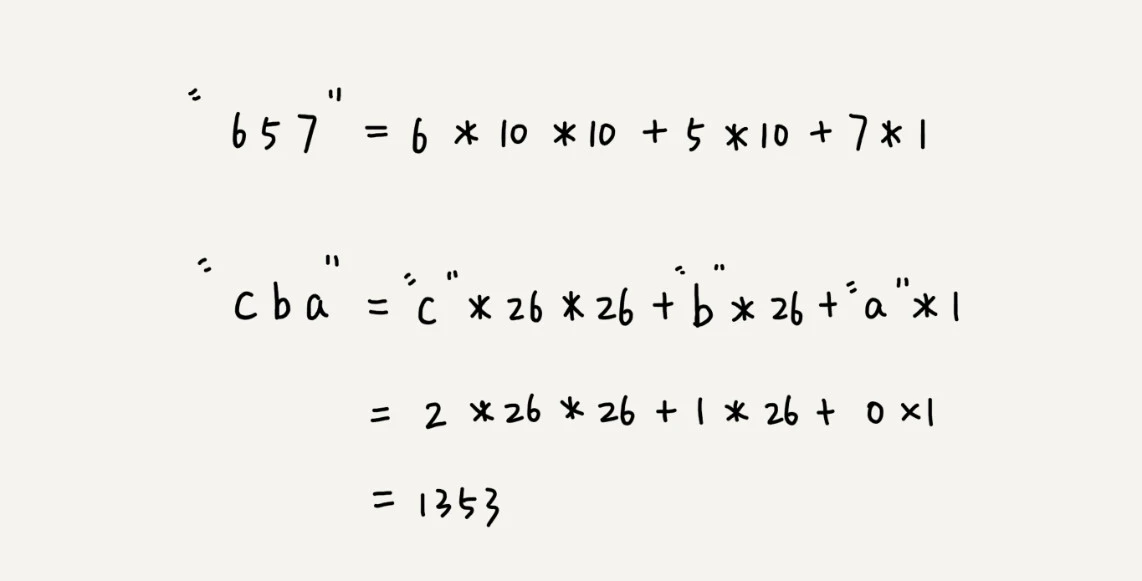
并且你会发现,子串与子串之间的哈希值是大部分都重叠的,对于S[i - 1]和S[i]两个相邻子串来说,S[i]的哈希值按权展开的形式是S[i] 的按权展开的基础上,去掉最大的,然后整体乘基数的一次方,再加上S[i]的最后一个字符的下一个字符的值。
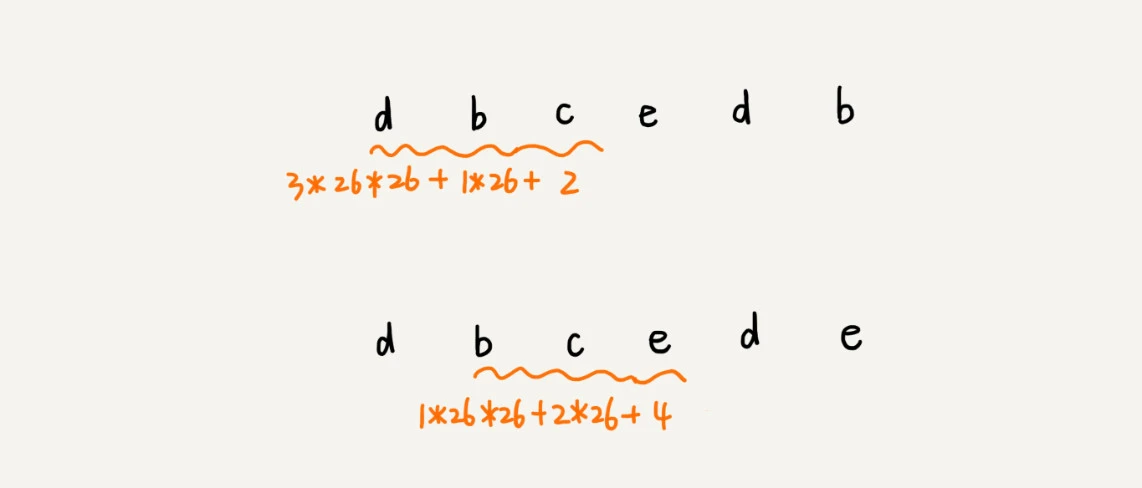
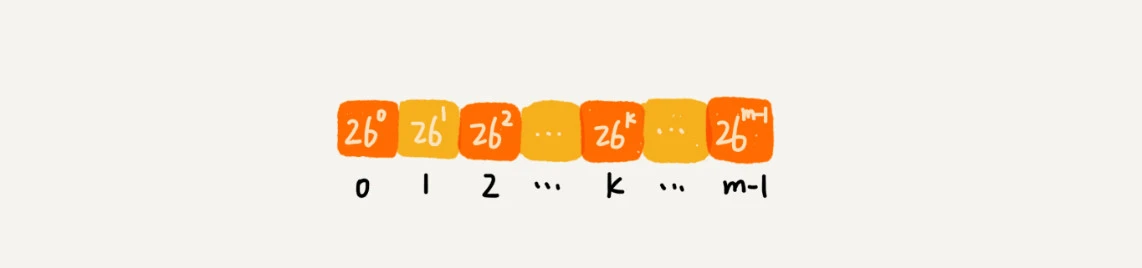
所以我们可以得出每个子串的的哈希值公式。

而且,还要注意,基数的各个次幂被反复使用且不被更改,所以我们提早算好,然后储存在一个数组中,当需要的时候,直接按下标读取就可以了,节省了很多时间。要是我们需要自己设置26个字母的值,26个字母对应的值也可以这样处理。
如果就看上面的例子,RK算法的时间复杂度包含了遍历字符串计算子串哈希值和比较所有子串和模式串,也就是O(n) + O(n) == O(2n)== O(n)。
但是,我们还要注意,哈希值是用整数存储的,所以有可能出现数值溢出,那么我们可以把字符串的每个字母全部加起来,加起来的值来当哈希值,这样溢出的概率就小得多了,当然,这会造成哈希冲突,所以我们这时的比较,当哈希值相同后,还要再比较以便子串和模式串本身,才能判断相不相同,极端情况下,会每一次都要在比较本身,也就是退化回了暴力匹配算法的时间复杂度,不过这也不多见,总体上,RK算法还是比BF算法效率高。
而且这是一种最简单的设计方法而已,还有许多的优化方法可以使哈希冲突概率更小,比如将每一个字母从小到大对应一个素数。
本文摘自 :https://www.cnblogs.com/
