 APP
APP
基本数据类型
整型int,long,字符型char,浮点型float、double,常用的基本数据类型就这些。
结构体
结构体可以理解为开发者用已有的数据类型为原料组合成的数据类型。例如数组就是这样的类型,数组其实就是我们开发者自己定义的一个数据类型,由多个相同数据类型的变量组合而所得,例如:
int a[maxSize];上面这句话相当于把maxSize个int型变量摆在一起,其中各个int型变量之间的关系由数组的下标反映。
试想,如果我们想要定义这样的数组,这个数组里面第一个变量是整形的,第二个变量是字符型的,第三个变量是浮点型的,此时就需要用到结构体。
结构体是系统提供给程序员制作新数据类型的一种机制,即可以用系统已有的不同的基本数据类型或用户定义的结构型,组合成用户需要的复杂数据类型。
刚刚提到的那个“奇怪的数组”,可以用结构体实现如下:
typedef struct
{
int a;
char b;
float c;
} MyType;现有语句如下:
MyType a[3];思考一下,上面这句话是什么意思呢?
显然,上面这句话定义了一个数组,这个数组由3个MyType类型的元素组成。
因为前面已经定义好了MyType类型的数据结构,MyType其实含有3个分量。
因此其实你可以把a类比为一个二维数组。
就好像下面这句话:
int b[3][3];上面这句话定义了一个名字为b的二维数组,二维数组可以看成一个一维数组,其数组元素也是一个一维数组。
b中取第一个元素的第一个分量:
b[0][0]a中取第一个元素的第一个分量:
a[0].a指针
变量里面装的是数据元素的内容。
指针里面装的是变量的地址。
通过指针可以找出变量在内存中的位置。
指针对于每种数据类型都有特定的定义方法,有专门指向int的指针,也有专门指向float的指针...
对于每种变量,其指针的定义规则类似:
int *a ;
char *b ;
float *c ;
MyType *d ;上面这段话表示:指向整形变量的指针a,指向字符型变量的指针b...
指针变量的定义只是在变量名前面多了一个*号
如果a是一个指针型变量,且这个指针型变量已经指向了一个变量b,则a中存放的就是变量b的地址
*a上面这句话表示取变量a中的内容,其实就相当于b
&b上面这句话表示取变量b的地址
a = &b ;上面这句话表示,将变量b的地址存放于指针a中,也可以叫做指针a指向b
链表结点的构造
链表结点有2个域,即数据域和指针域。数据域存放数据,指针域存放下一个结点的位置
链表结点的结构型定义为:
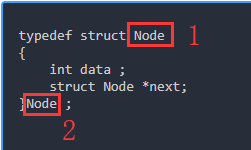
typedef struct Node
{
int data ;
struct Node *next;
}Node ;上面这段话的含义,请仔细理解一下
首先结构型的名字为Node
因为组成此结构体的成员中有一个指向和自己类型相同的变量的指针
并且内部要用自己来定义这个指针,所以要写成:
struct Node *next;凡是结构体a内部含义指针b
并且b是用来存放和a类型相同的结构体变量地址的指针类型(比如说链表的应用场景,链表中结点的指针域指向的也是结点变量)
则在定义结构体时,a的typedef struct语句之后要加上a这个结构体的名字,比如上面的Node
从语法上来说,这里的两个Node可以是不一样的,编译器也不会报错,但是从程序的可读性而言,最好这两处的名称是一样的
二叉树结点的构造
二叉树的结点其实和链表的结点差不多,直接看代码:
typedef stuct BTNode
{
int data ;
struct BTNode *lchid;
struct BTNode *rchild;
}BTNode;代码不难理解,和刚刚链表结点的构造差不多
当然如果要写得复杂点,还可以这样写:
typedef stuct BTNode
{
int data ;
struct BTNode *lchid;
struct BTNode *rchild;
}BTNode,*btnode;可以发现,后面多写了个*btnode,为什么要这样写呢?
考虑我们要定义一个结点指针p
如果用第一种定义方法(比较简单的那个),我们需要这样写:
BTNode *p ;如果你用第二种定义方法(比较复杂的那个,后面加了点东西)。我们可以这样写:
btnode p ;两种方法各有利弊:
简单的方法利于理解,但是你定义结点的时候需要多写一点,不容易搞混
复杂的方法写的时候复杂,但是定义的时候可以少写一点,容易搞混
下面介绍制作新结点的方法:
第一种方法这么写
BTNode BT ;访问的时候这样写(结构体变量直接取其分量)
x = BT.data ;该方法只用一句话就制作了一个结点
但是我们一般不会这么写,而采用如下方法
第二种方法这么写
BTNode *BT ;
BT = (BtNode*)malloc(sizeof(BTNode));首先定义一个节点的额指针BT
然后使用函数malloc申请一个结点的内存空间
最后让BT指向这片内存空间
其中malloc函数是系统提供的内存分配函数

当然BT可以离开这个结点而转向其他结点,所以说第二种方法比较灵活
访问的时候这样写(指向结构体变量的指针取结构体的分量)
x = BT -> data ;当然你也可以这样写
x = (*BT).data ;动态申请数组空间
刚刚是一次只申请一个结点,其实还有一次申请一组结点的方法
假设申请一个数组,数组内的元素类型为int型,长度为n,当然了,此处的int可以换成任意的数据类型,包括你自己定义的结构体类型
int *p ;
p = (int *)malloc(n * sizeof(int)) ;上述语句申请了一个,由p指向的,元素为int类型的,长度为n的动态数组
当然p指向的是数组中第一个元素的地址
取元素的时候,和一般的静态数组都是一样的
对比
对比制作结点的第二种方法和动态申请数组空间的方法,其不同之处仅仅在于,sizeof运算符前要乘以n
请注意sizeof是运算符,不是函数
typedef
typedef就是给现有的数据类型起一个别名
比如typedef struct{...} TypeA
就是给struct{...}取一个别名TypeA
# define
给常量取个别名
给0、1取ERROR、OK以及maxSize等常数的别名上用的比较多
本文摘自 :https://blog.51cto.com/u
