 APP
APP
论文阅读: Self-Training using Selection Network for Semi-supervised Learning
作者说明
基本信息
**1.标题:**Self-Training using Selection Network for Semi-supervised Learning
**2.作者:**Jisoo Jeong, Seungeui Lee, Nojun Kwak
**3.作者单位:**Seoul National University, Seoul, South Korea
**4.发表期刊/会议:**ICPRAM
**5.发表时间:**2020
**6.原文链接:**https://pdfs.semanticscholar.org/c204/77953fcd455943a24ff30035284246bcc6a2.pdf
Abstract
半监督学习(Semi-supervised learning, SSL)是一种有效利用大量未标记数据来提高有限标记数据条件下性能的研究。大多数传统的SSL方法都假设未标记数据的类包含在标记数据的类集中。此外,这些方法没有对无用的未标记样本进行分类,将所有未标记的数据都用于学习,不适合实际情况。在本文中,我们提出了一种称为选择性自训练(selective self-training, SST)的SSL方法,它有选择地决定是否在训练过程中包含每个未标记的样本。它被设计用于更实际的情况,即未标记数据的类与标记数据的类不同。对于标记样本和未标记样本共享同一类类别的传统SSL问题,所提出的方法不仅性能可与其他传统SSL算法相媲美,而且可以与其他SSL算法相结合。然传统方法不能应用于新的SSL问题,但我们的方法没有显示出任何性能下降,即使未标记数据的类与标记数据的类不同。
1.Introduction
近年来,机器学习在各个领域取得了很多成功,精细的数据集被认为是最重要的因素之一(Everingham等人,2010;Krizhevsky等人,2012;Russakovsky等人,2015)。由于我们无法发现潜在的真实数据分布,我们需要大量的样本来正确估计它(Nasrabadi,2007). 然而,建立一个大数据集需要大量的时间、成本和人力(Chapelle et al.2009;Odena等人,2018)。
半监督学习(Semi-supervised learning, SSL)是一种缓解数据收集和标注过程效率低的方法,它介于监督学习和非监督学习之间,因为在学习过程中同时使用了有标记和无标记的数据(Chapelle et al., 2009;Odena等人,2018)。它可以使用大量的未标记数据从较少的标记数据有效地学习模型(Zhu, 2006)。因此,SSL的意义在以往的文献中得到了广泛的研究(Zhu et al., 2003;Rosenberg等人,2005年;金玛等,2014;Rasmus et al., 2015;Odena, 2016;Akhmedova等人,2017年)。这些结果表明,在注释数据量不足的情况下,SSL可能是一种有用的方法。
然而,最近有一项研究讨论了传统SSL方法的局限性(Odena等人,2018)。他们指出,传统的SSL算法很难应用到实际应用中。特别是,传统的方法假设所有的未标记数据都属于训练标记数据的一类。使用未标记样本进行训练,这些样本的类分布与标记数据的类分布有显著差异,可能会降低传统SSL方法的性能。此外,无论何时有一组新的数据可用,都应该使用所有数据(包括out- class1数据)从头开始训练它们。
本文以分类任务为研究对象,提出了一种基于深度神经网络的选择性自训练(selective self-training, SST)方法来解决上述问题。为了使学习能够选择未标记数据,我们提出了一种基于深度神经网络的选择网络,该网络决定是否添加每个样本。与(Wang et al., 2018)不同,SST并没有直接使用分类结果进行数据选择。此外,我们采用了一种集成方法,它类似于协同训练方法(Blum and Mitchell, 1998),利用多个分类器的输出迭代地构建新的训练数据集。在我们的例子中,我们不使用多个分类器,而是将时间集成方法应用于选择网络。对于每个未标记的实例,比较选择网络的两个连续输出,以保持我们的训练数据干净。
此外,我们还发现每个类的样本数量之间的平衡对我们的网络性能非常重要。我们建议一个简单的启发式方法来平衡在类中选择的样本数量。通过所提出的选择方法,可以将可靠样本添加到训练集中,并排除包括类外数据在内的不确定样本。该方法的主要贡献可以总结如下:
- 对于传统SSL问题,所提出的SST方法不仅与其他传统SSL算法具有可比性,而且可以与其他算法相结合。
- 对于新的SSL问题,即使使用类外数据,提出的SST也没有显示任何性能下降。
- SST要求的超参数少,易于实现。
为了证明我们提出的方法的有效性,首先,我们进行了SST与其他几种最先进的SSL方法的分类误差比较实验(Laine和Aila, 2016;Tarvainen和Valpola, 2017;Luo et al., 2017;Miyato et al., 2017)在传统SSL设置中。其次,我们提出了一个新的实验设置,以调查我们的方法是否更适用于现实世界的情况。(Odena et al., 2018)的实验设置在类别内和类别外中取样。在本文的实验设置中,我们均匀地对所有类中的未标记实例进行采样。我们使用三个公共基准数据集:CIFAR-10、CIFAR-100 (Krizhevsky and Hinton, 2009)和SVHN (Netzer et al., 2011)来评估提出的SST的性能。
2.BACKGROUND
在这一部分中,我们介绍了我们的研究背景。首先,我们介绍一些自我训练的方法(McLachlan, 1975;朱,2007;朱和戈德堡,2009),这是我们工作的基础。然后我们描述了基于一致性正则化的算法,如Π模型和时间集成(Laine和Aila, 2016)。
2.1 Self-training
自训练方法长期以来被用于半监督学习(McLachlan, 1975;Rosenberg等人,2005年;朱,2007;Zhu and Goldberg, 2009)。它是一种重采样技术,根据置信度对未标记的训练样本进行重复标注,并使用所选的伪标签数据对自身进行重训练。这个过程可以形式化如下。(i)用标记数据训练模型。(ii)用学习到的模型预测未标记数据。(iii)用标记的和选定的伪标签数据对模型进行再训练。重复最后两个步骤。
然而,大多数的自训练方法都假设有标签的和无标签的数据来自相同的分布。因此,在现实场景中,根据标签数据的分布情况,一些可能性较低的实例不可避免地有被误分类的可能。因此,这些错误的样本明显导致了下一个训练步骤中更差的结果。为了解决这一问题,我们采用集成和平衡的方法来选择可靠的样本。
Deep Semi-Supervised Semantic Segmentation. 标注质量在技术性能中起着至关重要的作用。特别是在语义分割的任务中,标签的开销过大。例如,来自分割基准数据集Cityspaces[6]的一张分辨率为1024x2048的图像,涉及超过1M的像素标签,容易出现注释错误,需要考虑像素模糊的问题。SSL非常适合手头的任务,因为前面的方法依赖于一组很小的标签。用于语义分割的深层SSL最近只在少数工作中进行了探索。
早期的技术依赖于GANs[12]原理。
[41]作者提出通过生成gan型合成图像来扩大训练集,以丰富特征空间,加强无标记样本和有标记样本之间的关系。Hung等人[17]提出一种基于GAN的预测概率图与地面真值分割的区分技术。类似地,Mittal等人[31]提出了一个双分支解决方案,包括:i)为输入样本生成每像素类标签的GAN分支和ii)多标签Mean Teacher[43]分支,以消除假阳性预测。
最近,[11]的作者将CutMix[48]扩展到语义分割的上下文中。在这篇论文中,作者应用了强增强的原理,包括Cutout,从图像分类的发现。[36]的作者强调了基于特征、基于预测和随机扰动之间的一致性。Ke等人的[20]使用了缺陷概率图,并将双学生[21]扩展到像素级任务。在[10]中提出了一种基于伪标签的离线自训练方案,增强了有标记集和无标记集之间的一致性。
2.2 Consistency Regularization

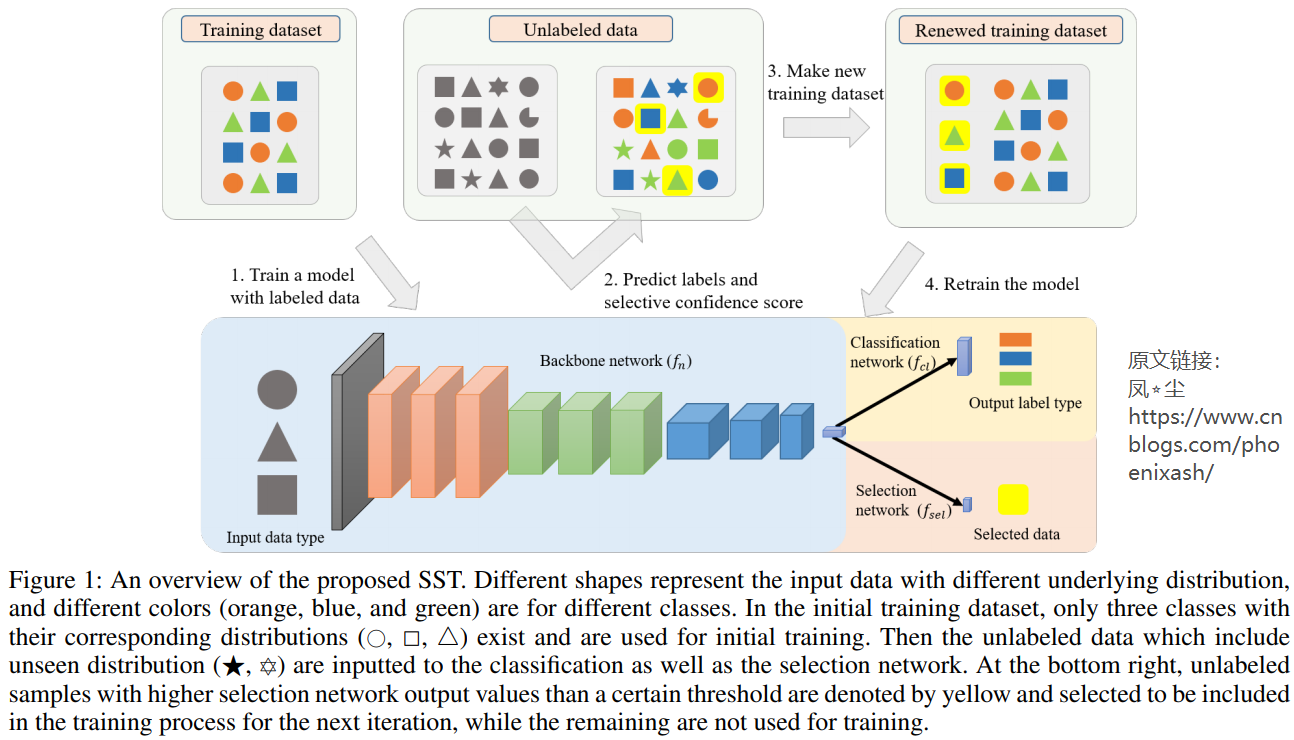
3. METHOD
本文摘自 :https://blog.51cto.com/u
