 APP
APP
1. 背景
最近准备学习netty,发现自己对NIO相关的理论知之甚少。本文对NIO中多路复用的来龙去脉经过了详细的分析,通过实战抓取系统调用日志,加深对底层理论的理解。在此基础上,梳理了BIO/NIO相关的流程图,加强对NIO的整体流程理解。
2. 进程和线程
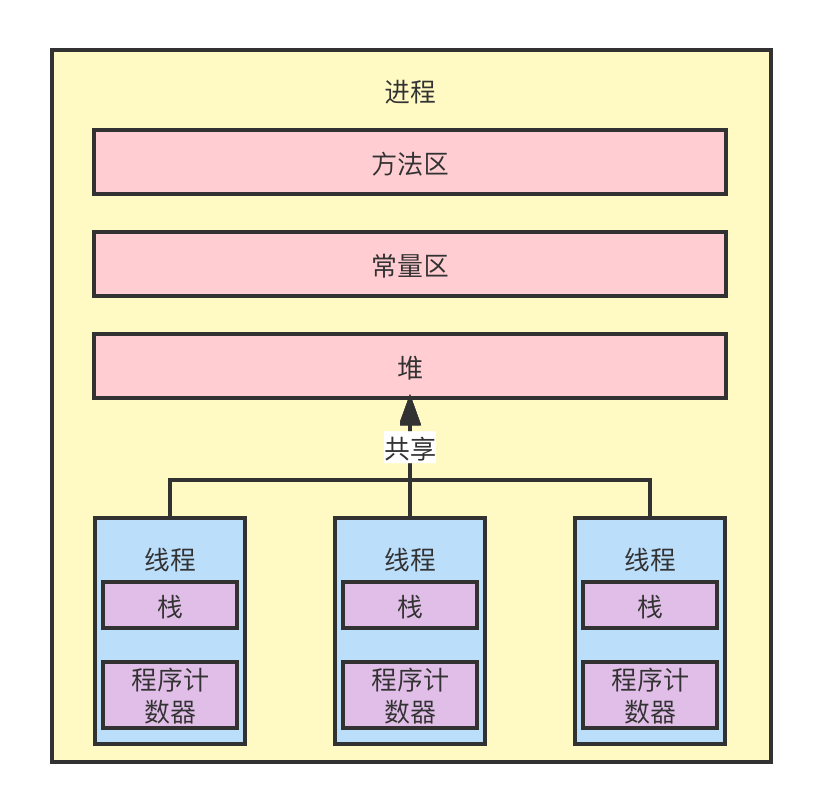
CPU每经过一个时间片,随机调度并执行一个线程。这些线程共用了进程的堆、常量区、方法区。每个线程只占用内存中的少量内存空间,用于存放个字的栈和程序计数器。线程和进程的资源关系如下图:
3. 内核态和用户态
机器启动时,linux首先加载内核代码,启动内核进程。创建全局描述符表,用于记录内核的内存区域和用户程序的内存区域。内核用于控制各种硬件,非常敏感,不允许用户程序直接调用内核代码,访问内核的内存区域。用户程序必须通过linux系统调用,经过linux的验证后,CPU切换到内核线程,代替用户程序执行对应功能。
系统调用过程如下:
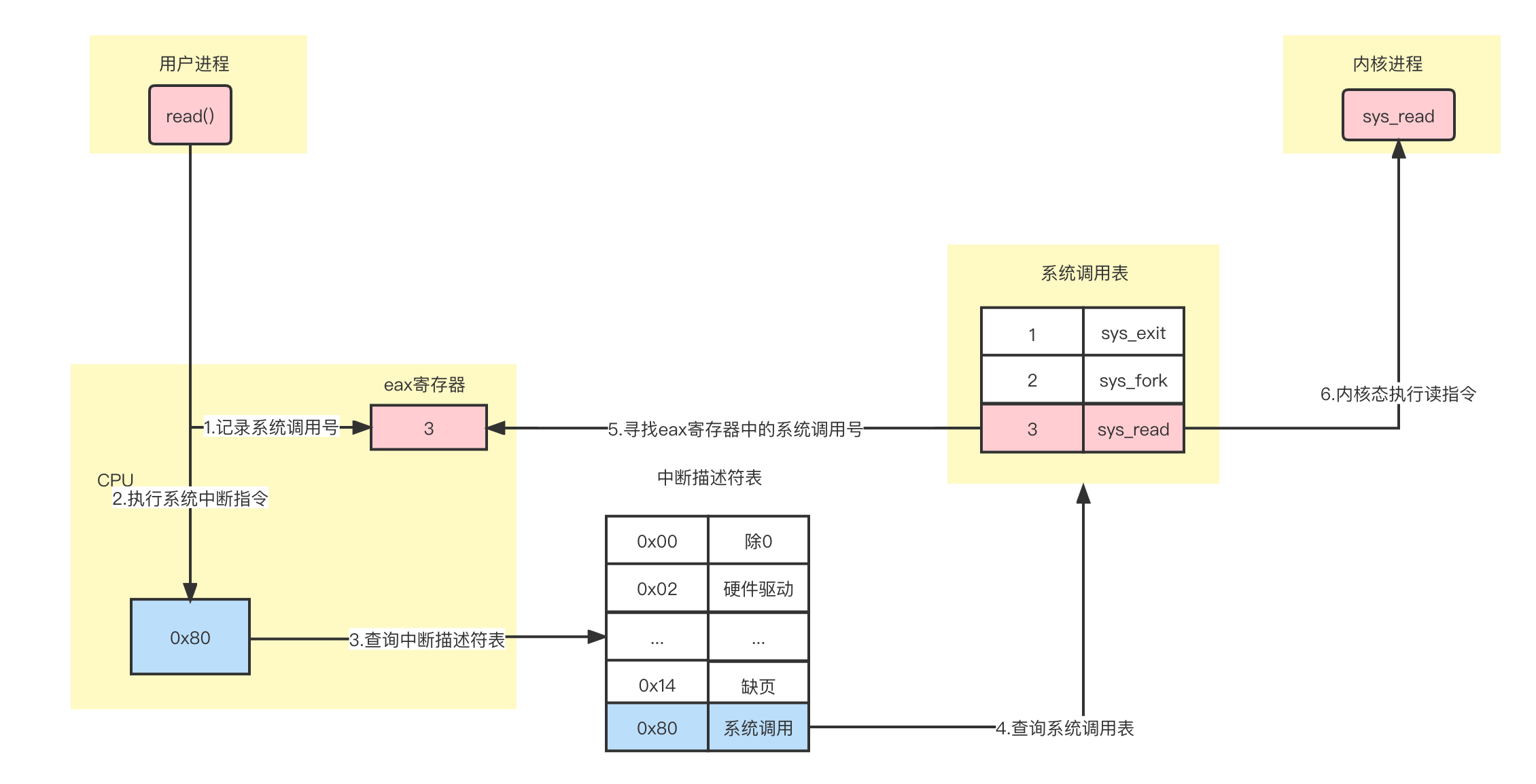
具体步骤为:
- 用于进程代码内执行read()方法。read其实就是要执行系统调用了,在CPU的eax寄存器中保存对应的系统调用号3。
- CPU执行系统中断指令
0x80,查询中断描述符表,该指令表示系统调用。 - CPU查询系统调用表,发现eax寄存器中的3表示读取指令,切换内核线程执行读取操作,最后将结果返回给用户程序。
4. 系统调用实战
4.1 BIO
通过Java编写SocketServer服务端代码,Socket服务端以BIO阻塞的方式接受客户端连接,并阻塞地接受客户端数据,打印数据,打印完,维持线程不退出。

4.1.1 启动SocketServerBIO服务端
启动SocketServerBIO程序,并通过strace命令跟踪系统调用的执行。-ff -o socket_file参数表示将系统调用的执行结果打印到socket_file文件中,将进程/线程的跟踪结果输出到相应的socket_file.pid上:
strace -ff -o socket_file /home/hadoop/jdk8/bin/java SocketServerBIO启动BIO服务端:
创建了一个5735的进程号:
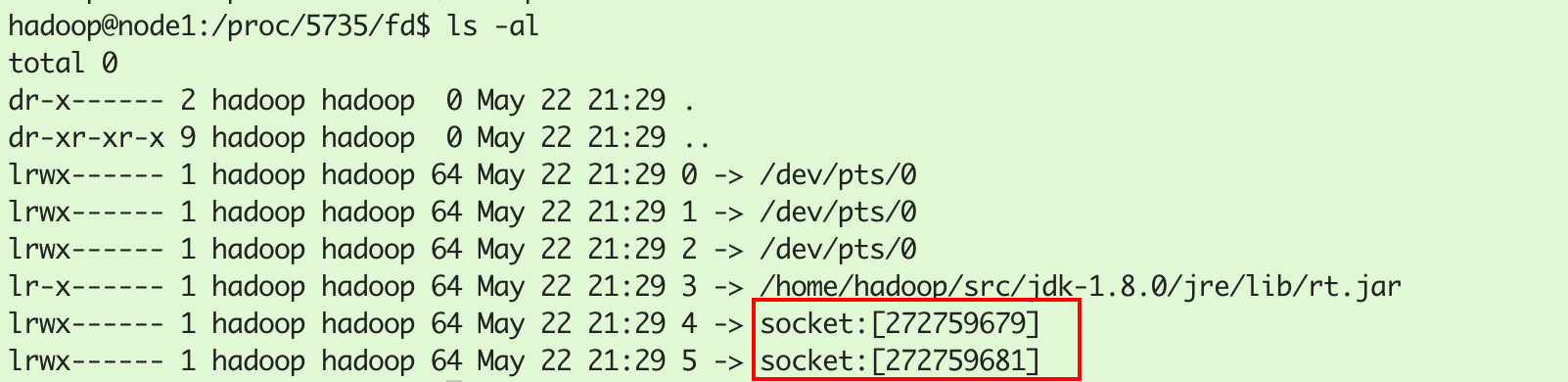
通过/proc/5735/fd可以看到该进程创建了两个Socket,分别是IPv4的Socket和IPv6的Socket(不重要,不讨论):
通过nestat -antp命令可以查看socket详细信息。即SocketServerBIO进程正在监听8888端口:

查看strace输出文件,它以进程号5735开始,socket_file.5735记录进程的系统调用过程,socket_file.5736为主线程的系统调用过程,后面的socket_file记录的是子线程的系统调用过程: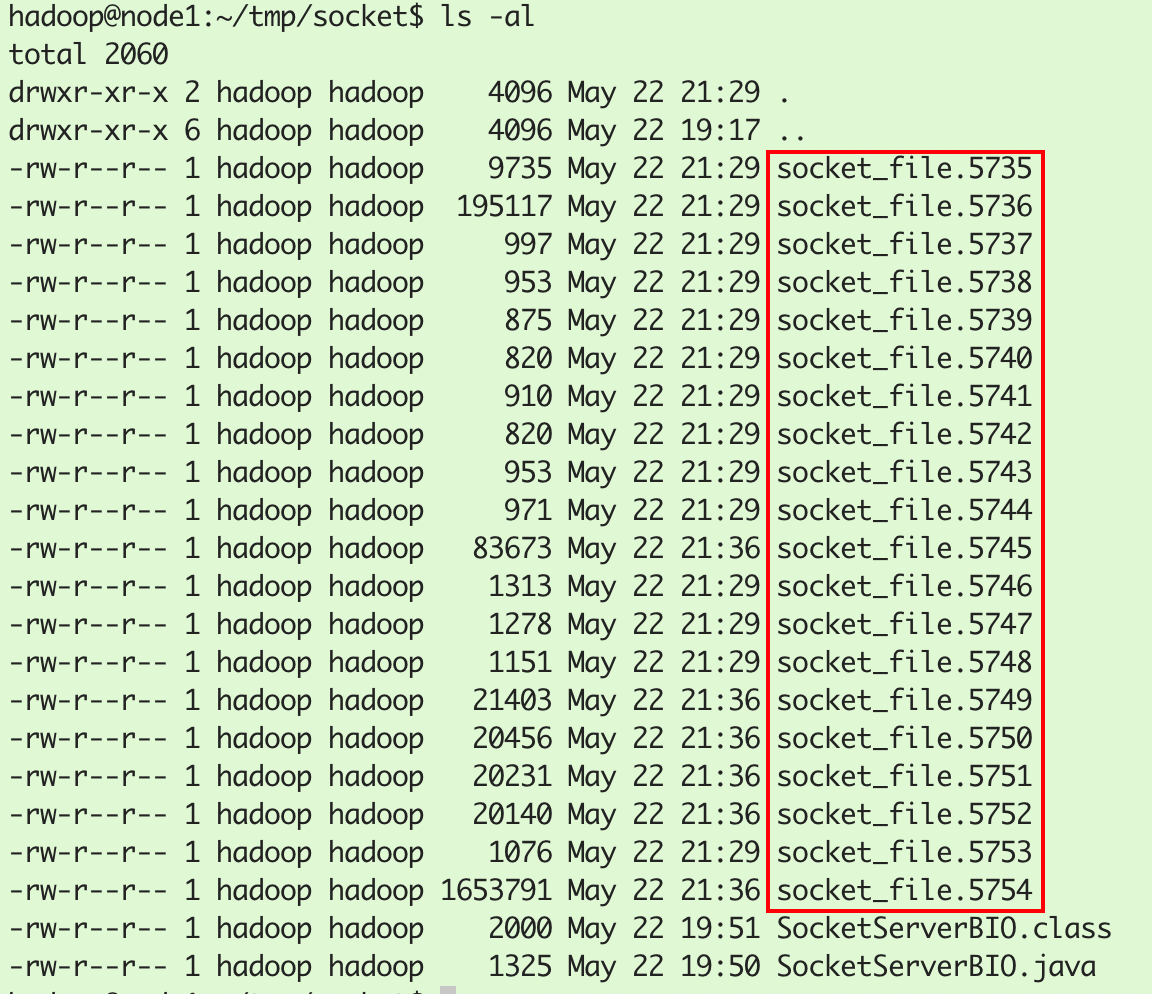
通过socket_file.5736文件可以看到,主线程创建文件描述符分别是4(不重要,不讨论)和5:

服务端创建socket,对应文件描述符为5:
绑定8888端口,并监听该端口:
4.1.2 客户端发起连接
客户端向8888端口发起连接请求nc localhost 8888
可以看到服务端接受到了来自客户端36204端口的socket连接请求:
此时服务端进程5735新增了一个socket: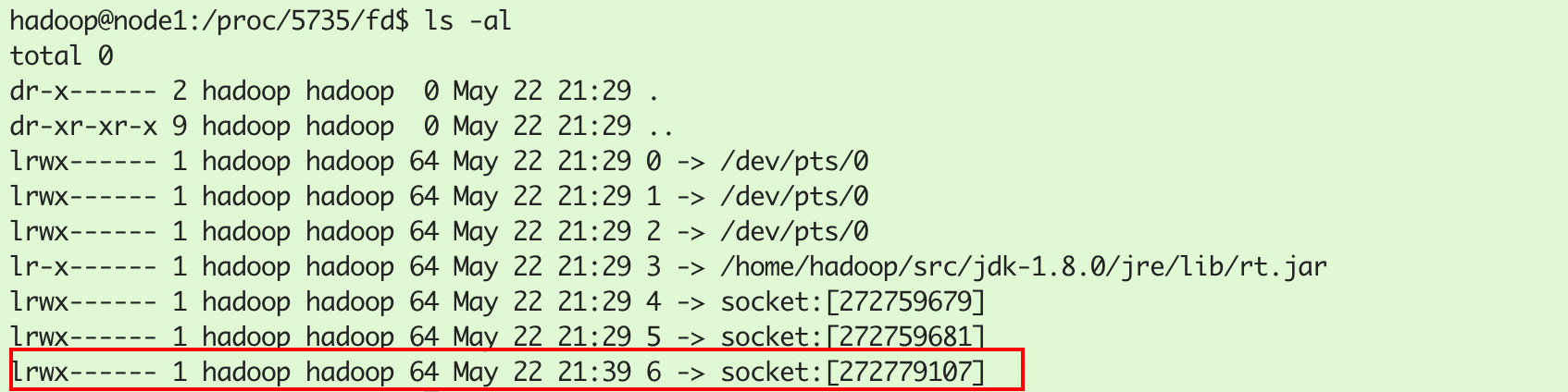
通过netstat -antp查看该socket详细信息:

新增两个socket连接,其实是一个意思,分别表示服务端创建了一个socket用于接受本机的36204端口的客户端的请求;客户端创建socket,使用36204端口向服务端8888端口发送请求。
通过socket_file.5736文件可以看到,服务端接受了36204端口的客户端请求,创建socket,并创建6号文件描述符,指向该socket:
接受socket请求后,程序代码里面创建子线程需要通过系统调用clone()方法,生成的子线程ID号为7356:
同时,strace命令也创建了7356线程对应的系统调用跟踪信息文件socket_file.7356: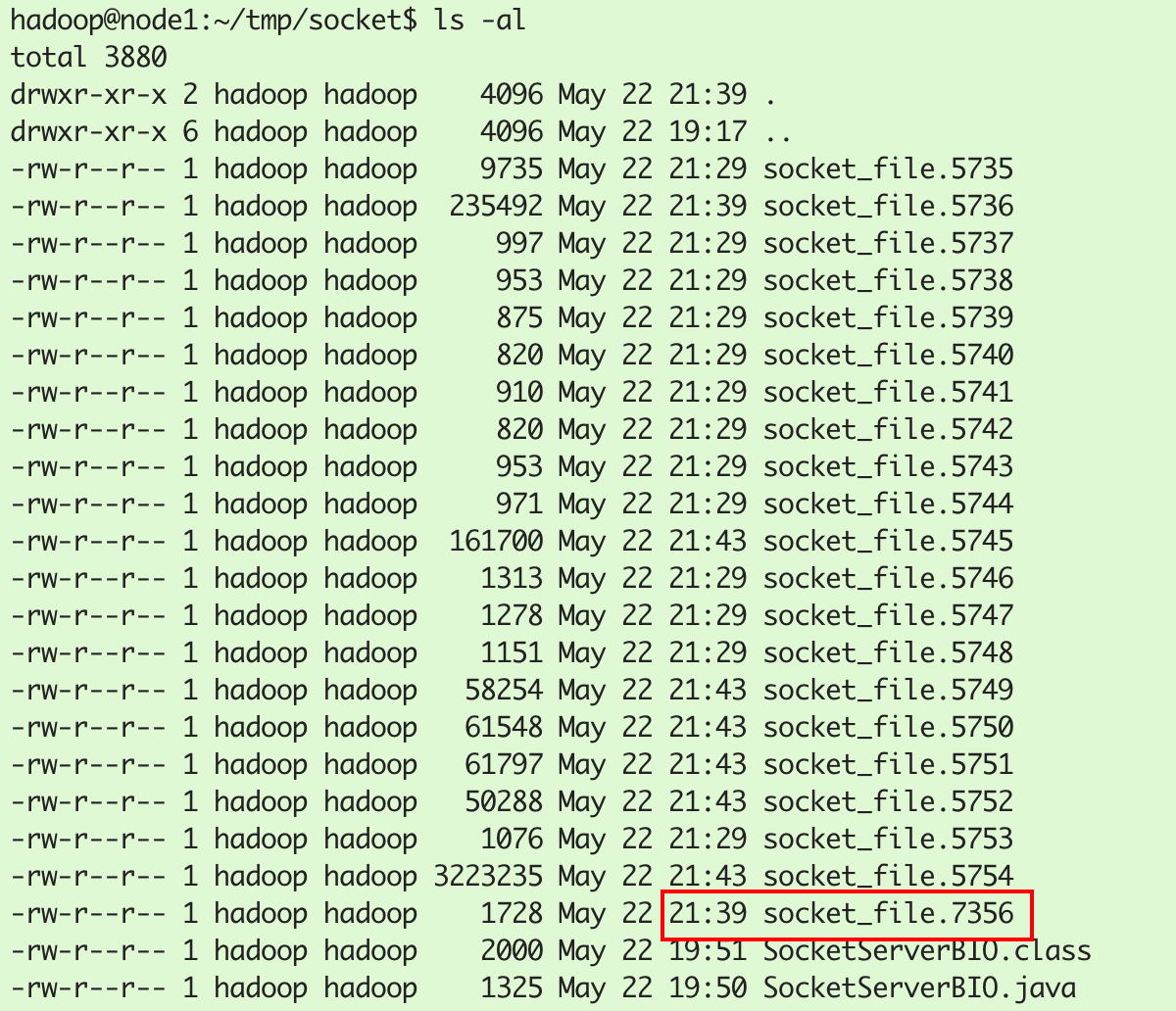
4.1.3 客户端发送数据

服务端接受数据并打印:
查看socket_file.7356文件,发现该线程接受了hello world的消息,并等待下一次数据传输: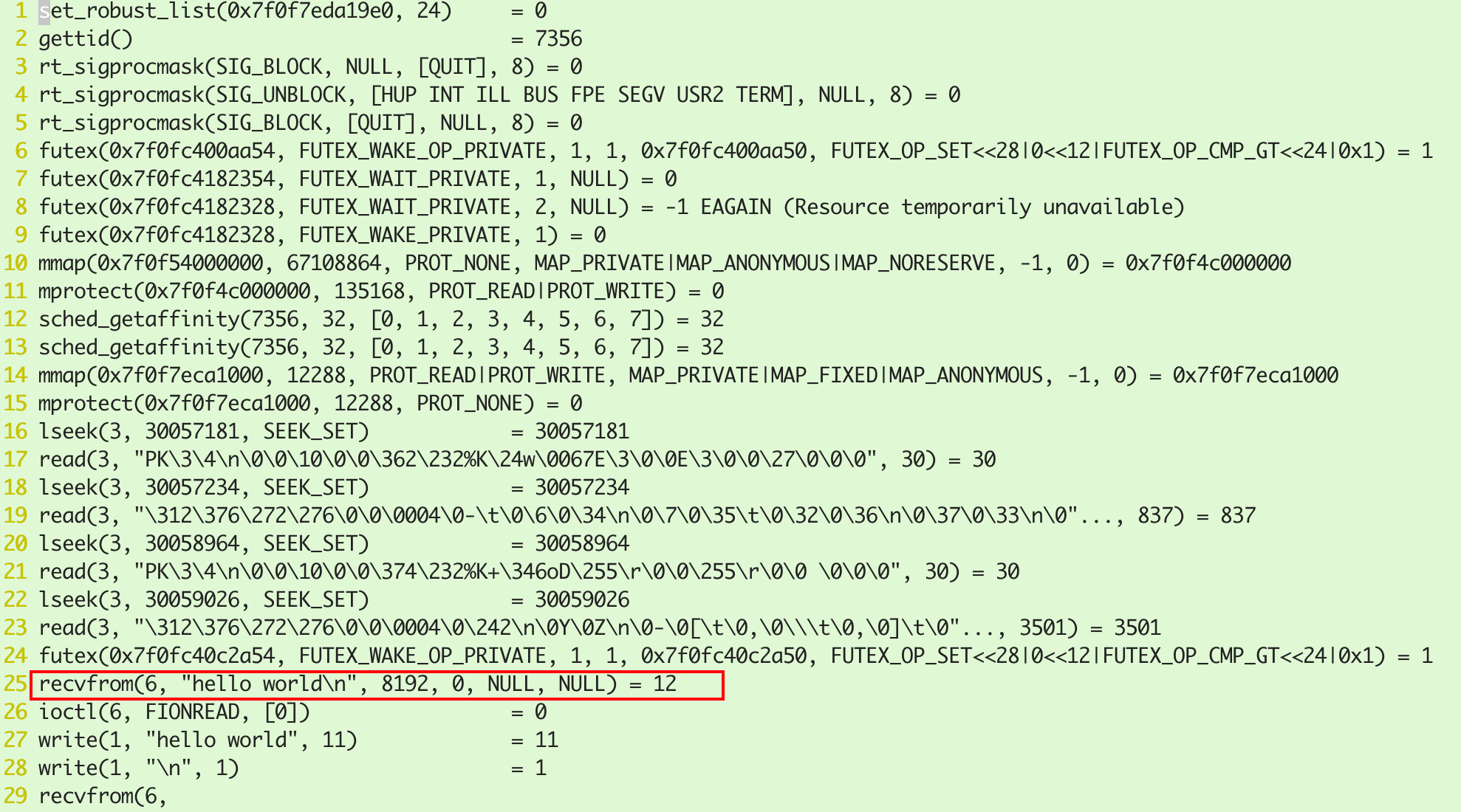
4.1.4 BIO总结
由于BIO的accept方法是阻塞的,因此单线程阻塞时,如果已经建立的连接发送数据到服务端,这时服务端由于阻塞不能处理该数据,因此BIO模式下,服务器性能非常差。这时只有为每个建立的socket创建处理数据的子线程。线程模型如下:
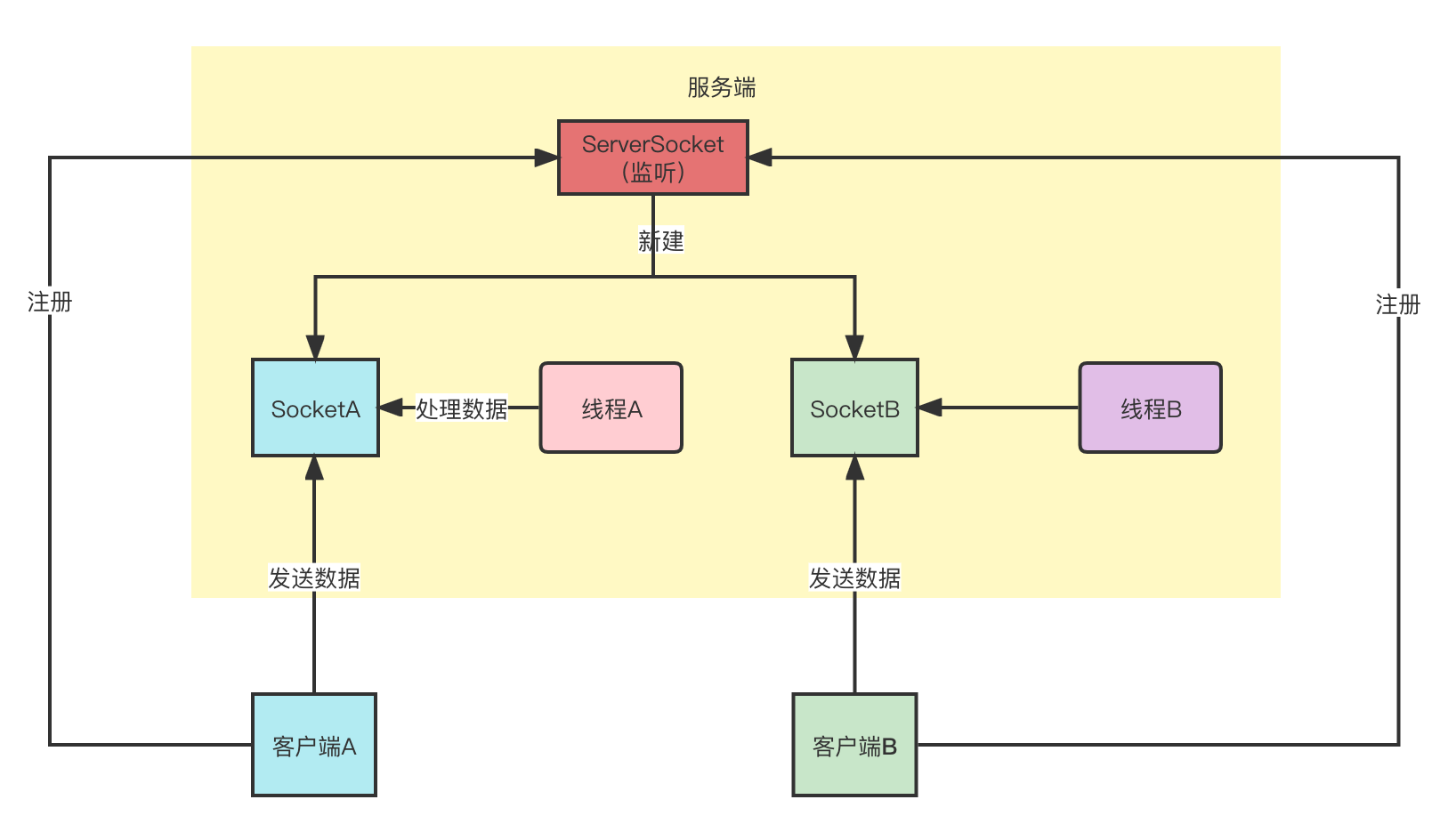
它的缺点就是创建子线程浪费资源,可以通过NIO方式避免创建为每个连接创建子线程。
4.2 非阻塞NIO
通过Java编写SocketServer服务端代码,Socket服务端以NIO非阻塞的方式接受客户端连接,并非阻塞地接受客户端的数据,打印数据。全程只有一个主线程工作。

4.2.1 启动服务端
依然使用strace -ff -o socket_file /home/hadoop/jdk8/bin/java SocketServerNIO命令启动NIO服务端:

创建了ID号为29050的进程:
strace系统调用跟踪到socket_file文件中,如下所示:
socket_file.29051文件为主线程的系统调用日志。可以发现NIO Socket系统调用中,对ServerSocket设置了NONBLOCK,即非阻塞(而BIO中,默认就是阻塞的):

此时可以看到accept系统调用持续进行调用,-1表示没有连接:

4.2.2 客户端连接

服务端接受客户端请求,并建立连接
此时并没有创建新线程:
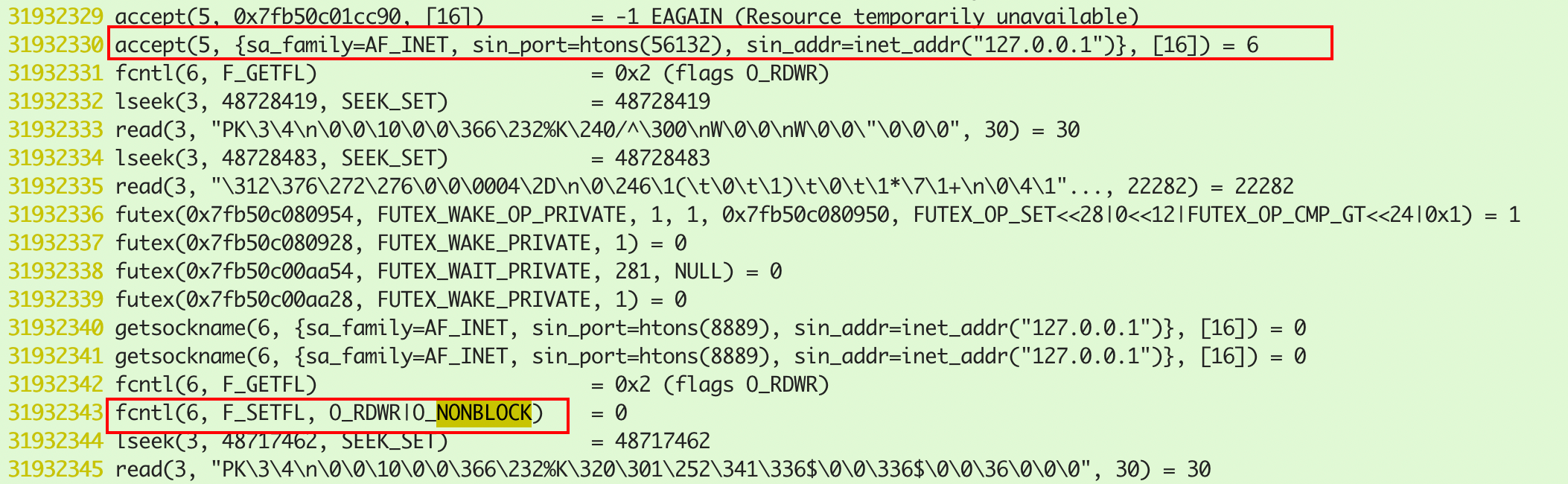
socket_file.29051主线程系统调用日志创建了新的socket连接,用于与客户端通信,文件描述符ID为6,并设置NONBLOCK非阻塞:
4.2.3 客户端发送数据

服务端打印了该数据:
socket_file.29051主线程系统调用日志中接受了该数据。可以看到上面的read返回-1,表示read没有读取到数据,这表明read是是非阻塞的: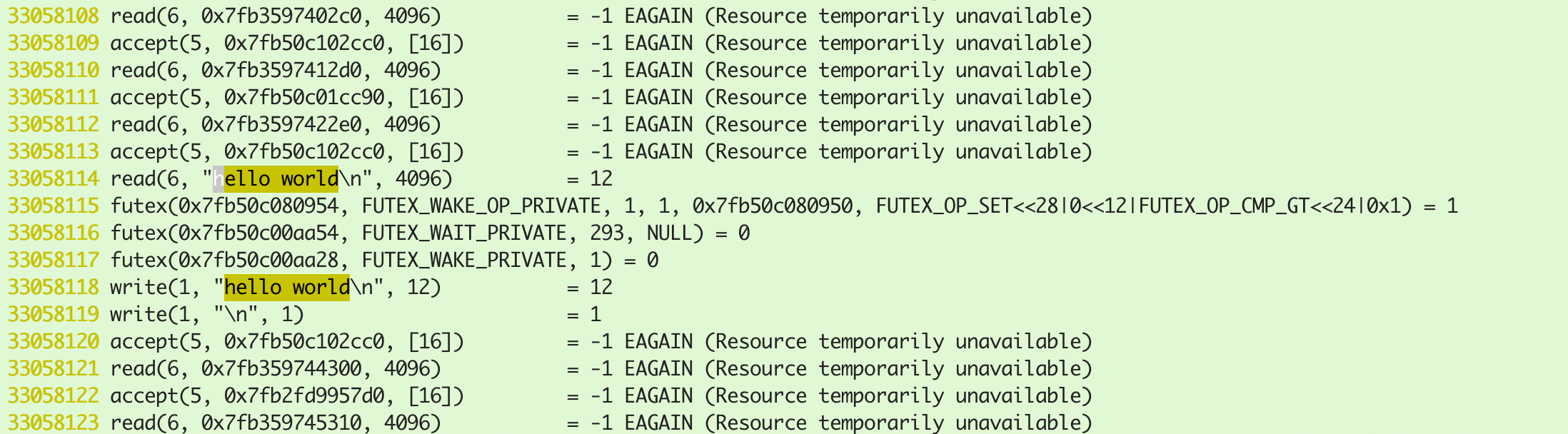
4.2.4 NIO总结
通过设置NONBLOCK非阻塞,避免为每个socket创建对应的线程。
4.3 C10K问题
随着互联网的普及,应用的用户群体几何倍增长,此时服务器性能问题就出现。最初的服务器是基于进程/线程模型。
- 对于BIO,新到来一个TCP连接,就需要分配一个线程。假如有C10K,就需要创建1W个线程,可想而知单机是无法承受的。因此优化BIO为NIO。
- 对于NIO,只有一个线程。如果有C10K个连接,每次就需要进行1w次循环遍历,处理每个连接的数据,每次遍历都是一次系统调用。其实这种O(n)次数据的处理可以优化成O(1),O(1)表示固定次数的遍历。
C10K全称为10000 clients,即服务端处理1w个客户端连接时,如何处理这么多连接,避免服务器出现性能问题。
4.4 多路复用NIO
在4.3节非阻塞IO的代码中可以发现,每次在用户态都会遍历所有socket,事件复杂度为O(n),可以通过多路复用NIO代码,在操作系统内核中,让多路复用器遍历所有socket,返回发生了状态变化的m个socket,用户程序每次只需要执行m次遍历即可。这样将遍历次数从n次优化成为固定的m次。即将事件复杂度从O(n)优化成为O(1)。下面看看多路复用器实现的发展历程。
4.4.1 select
Select是初期的多路复用器实现。它们的接口如下:
int select (int maxfdp, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
参数解释:
- maxfdp:表示要检查文件描述符的范围,它的值为最大的文件描述+1。例如,检查4和17两个文件描述符,maxfdp大小就是18。
- readfds:检查readfds包含的文件描述符中,哪些文件描述符可读。
- writefds:检查writefds包含的文件描述符中,哪些文件描述符可写。
- exceptfds:检查exceptfds包含的文件描述符中,哪些文件描述符有异常要处理。
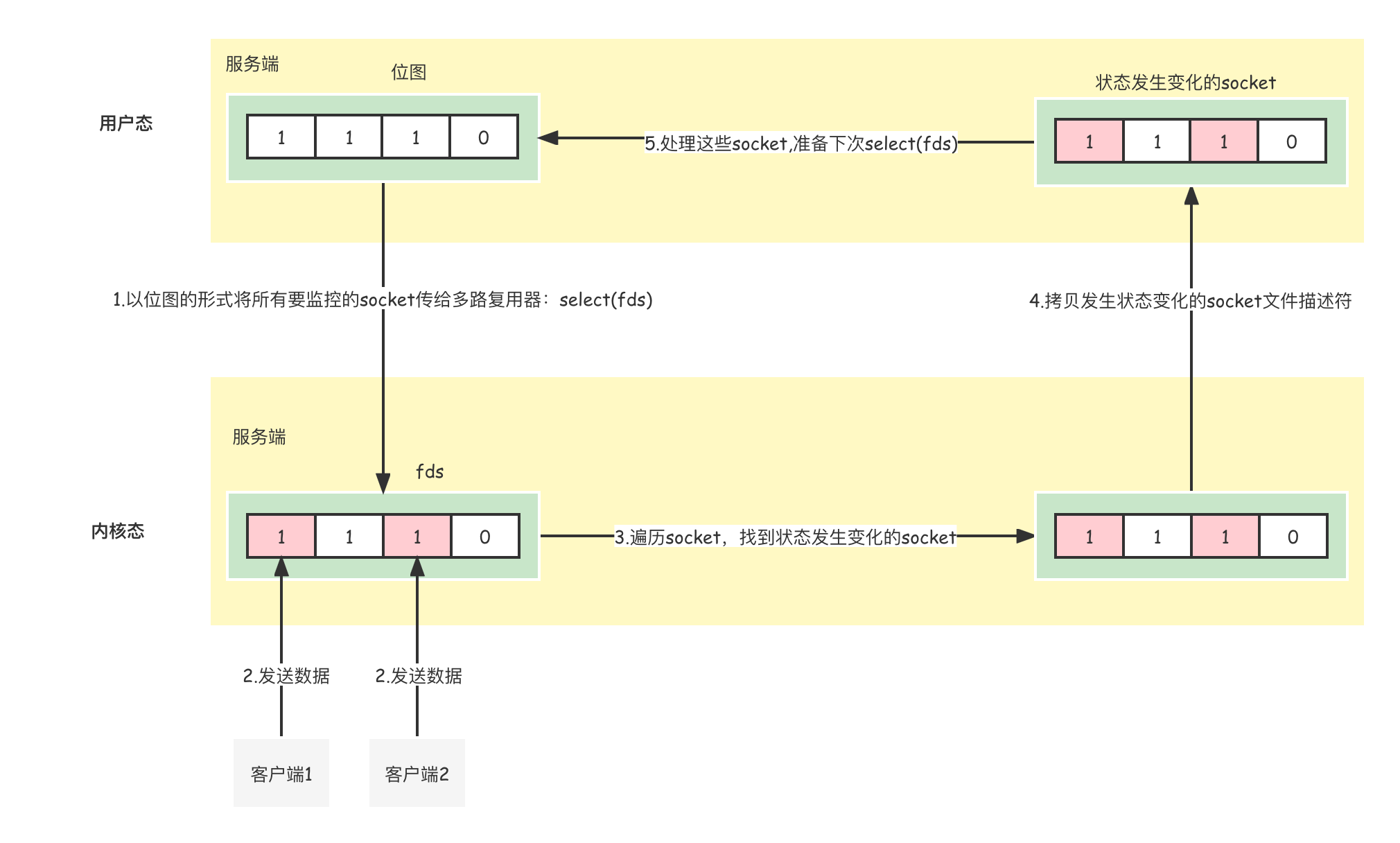
fd_set位图
传入select方法的参数类型为fd_set,它是位图类型。32位机器的位图类型默认占1024位,64位的机器默认占2048位。以32位机器为例,每一位的下标表示一个文件描述符,例如1011就表示0,1,4号文件描述符。可以看到,位图通过1024位就可以表示一个0~1023的数组,非常节省空间。但是1024位的位图表示数组的范围只有0~1023,如果要监控文件描述符超过1024,应该用Poll实现的多路复用器。
select方法中的位图举例:
- 当select函数readfds参数为1001 0101时,是用户想告诉内核,需要监视文件描述符等于0,2,4,7的文件的读事件的状态。
- 当select函数writefds参数为1000 0001时,是用户想告诉内核,需要监视文件描述符等于0,7的文件的写事件的状态。
select多路复用的流程如下:
4.4.2 poll
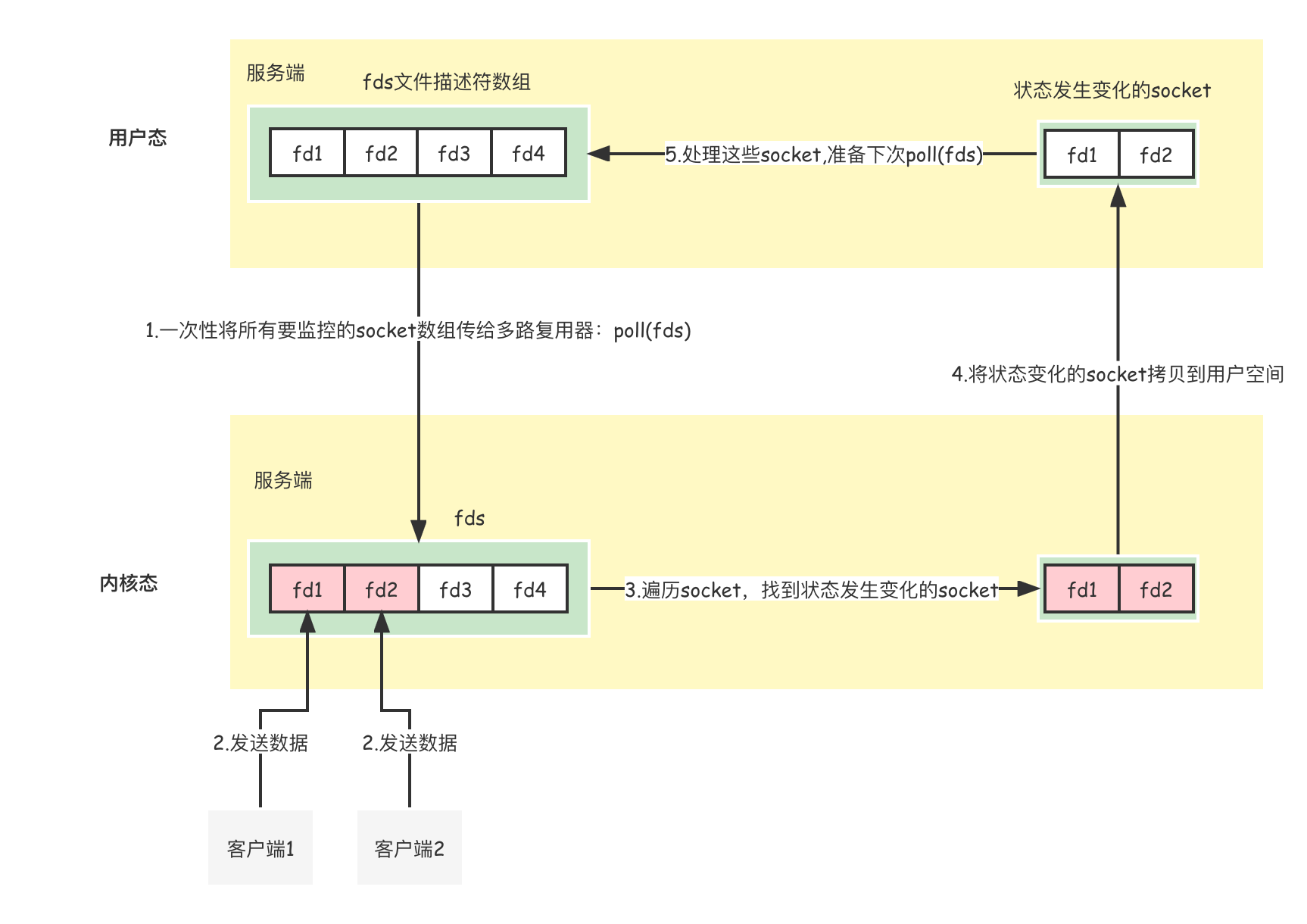
poll将输入参数从位图改成数组,如下所示:
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
这意味着虽然数组占用的空间更大,使用poll能够监控的文件描述符不存在上限。select多路复用的流程如下:
4.4.3 select和poll总结
- 每次调用select和poll都是一次性传入所有要监控的文件描述符,只发生一次系统调用。
- 在内核态,内核进程通过O(n)的时间复杂度遍历文件描述符的状态。比较浪费CPU,不过这比用户态O(n)遍历要好,因为用户态每次遍历还要进行系统调用。
- 内核将发生状态变化的文件描述符拷贝到内核空间。
- 用户遍历状态变化后的socket,为固定大小m,用户态以O(1)时间复杂度遍历这些socket。
4.4.4 epoll
上述select和poll的缺点是,内核要以O(n)的时间复杂度遍历文件描述符,当客户端连接越多,集合越大,消耗的CPU资源比较高,epoll就解决了这个问题。在内核版本>=2.6则,具体的SelectorProvider为EPollSelectorProvider,否则为默认的PollSelectorProvider。可见select和poll已经过时了,epoll才是主流。
epoll原理
完成epoll操作一共有三个步骤,即三个函数互相配合:
//建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
int epoll_create(int size);
//向epoll对象中添加连接的套接字;
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待事件的产生,收集发生事件的连接,类似于select()调用。
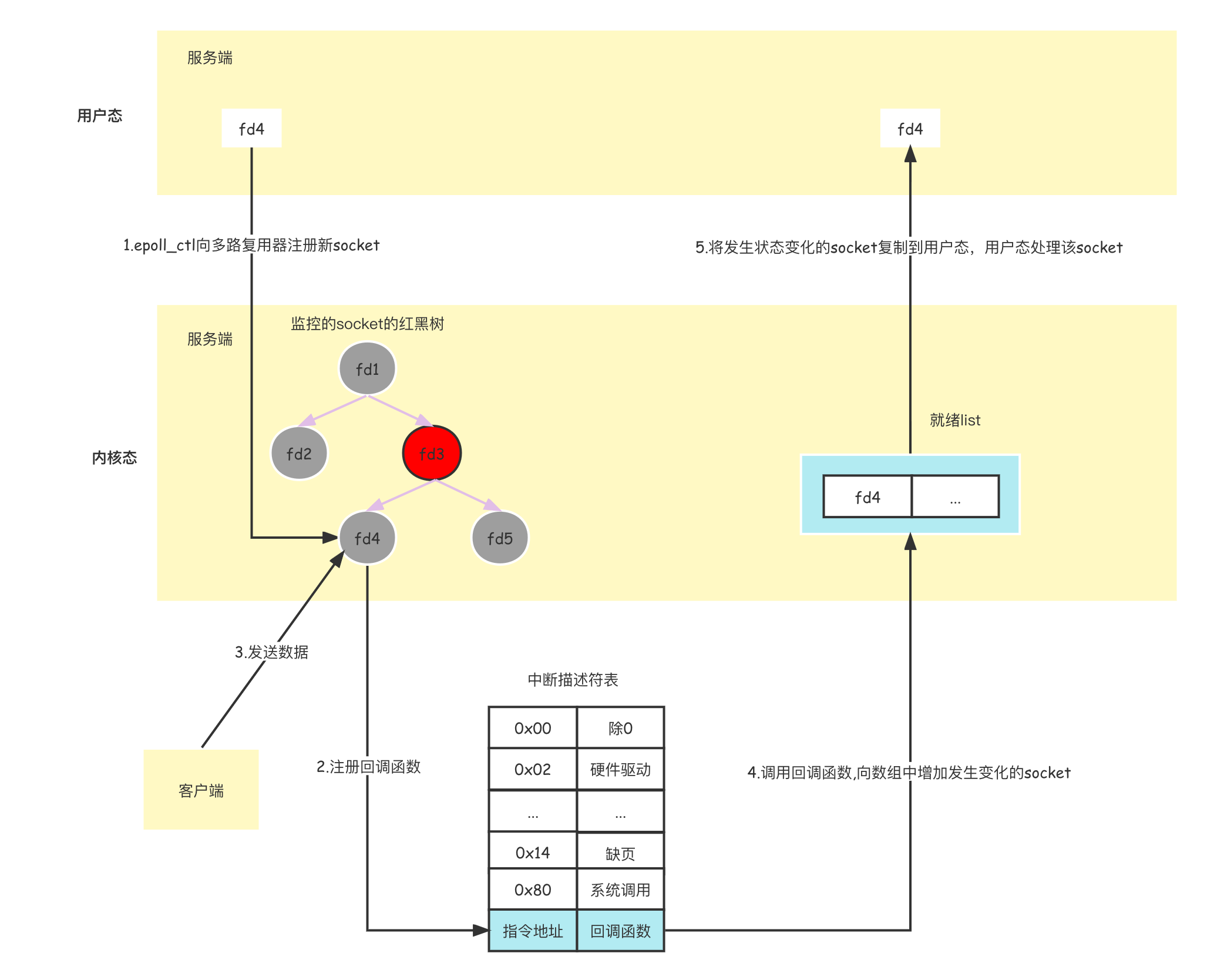
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout); - 先用epoll_create创建一个epoll对象epfd,再通过epoll_ctl将需要监视的socket添加到epfd中,最后调用epoll_wait等待数据。
- 当执行 epoll_create 时 ,系统会在内核cache创建一个红黑树和就绪链表。
- 当执行epoll_ctl放入socket时 ,epoll会检测上面的红黑树是否存在这个socket,存在的话就立即返回,不存在就添加。然后给内核中断处理程序注册一个回调函数,告诉内核,如果这个socket句柄的中断到了,就把它放到准备就绪list链表里。如果网卡有数据到达,向cpu发出中断信号,cpu响应中断,中断程序就会执行前面的回调函数。红黑树是自平衡的二叉排序树,适合频繁插入和删除的场景。增删查一般时间复杂度是 O(logn)。
- epoll_wait就只检查就绪链表,如果链表不为空,就返回就绪链表中就绪的socket,否则就等待。只将有事件发生的 Socket 集合传递给应用程序,不需要像 select/poll 那样轮询扫描整个集合(包含有和无事件的 Socket ),大大提高了检测的效率。
上述流程如下所示:
触发事件
epoll有两种工作模式:LT(level-triggered,水平触发)模式和ET(edge-triggered,边缘触发)模式。
水平触发(level-trggered):处于某个状态时一直触发。
- 只要文件描述符关联的读内核缓冲区非空,有数据可以读取,就一直从epoll_wait中苏醒并发出可读信号进行通知。
- 只要文件描述符关联的内核写缓冲区不满,有空间可以写入,就一直从epoll_wait中苏醒发出可写信号进行通知。
边缘触发(edge-triggered):在状态转换的边缘触发一次。
- 当文件描述符关联的读内核缓冲区由空转化为非空的时候,则从epoll_wait中苏醒发出可读信号进行通知。
- 当文件描述符关联的写内核缓冲区由满转化为不满的时候,则从epoll_wait中苏醒发出可写信号进行通知。
简单的说,ET模式在可读和可写时仅仅通知一次,而LT模式则会在条件满足可读和可写时一直通知。比如,某个socket的内核缓冲区中从没有数据变成了有2k数据,此时ET模式和LT模式都会进行通知,随后应用程序可以读取其中的数据,假设只读取了1k,缓冲区中还剩1k,此时缓冲区还是可读的,如果再次检查,那么ET模式则不会通知,而LT模式则会再次通知。
ET模式的性能比LT模式更好,因为如果系统中有大量你不需要读写的就绪文件描述符,使用LT模式之后每次epoll_wait它们都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!而如果使用ET模式,则在不会进行第二次通知,系统不会充斥大量你不关心的就绪文件描述符。
所以,使用ET模式时需要一次性的把缓冲区的数据读完为止,也就是一直读,直到读到EGAIN(EGAIN说明缓冲区已经空了)为止,否则可能出现读取数据不完整的问题。
同理,LT模式可以处理阻塞和非阻塞套接字,而ET模式只支持非阻塞套接字,因为如果是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行了。
默认情况下,select、poll都只支持LT模式,epoll采用 LT模式工作,可以设置为ET模式。
编写多路复用服务端代码:
通过Java编写SocketServer服务端代码,创建多路复用器,将所有socket注册到多路复用器中,多路复用器负责监听所有socket状态变化,主线程通过获取socket状态,进行相应处理即可。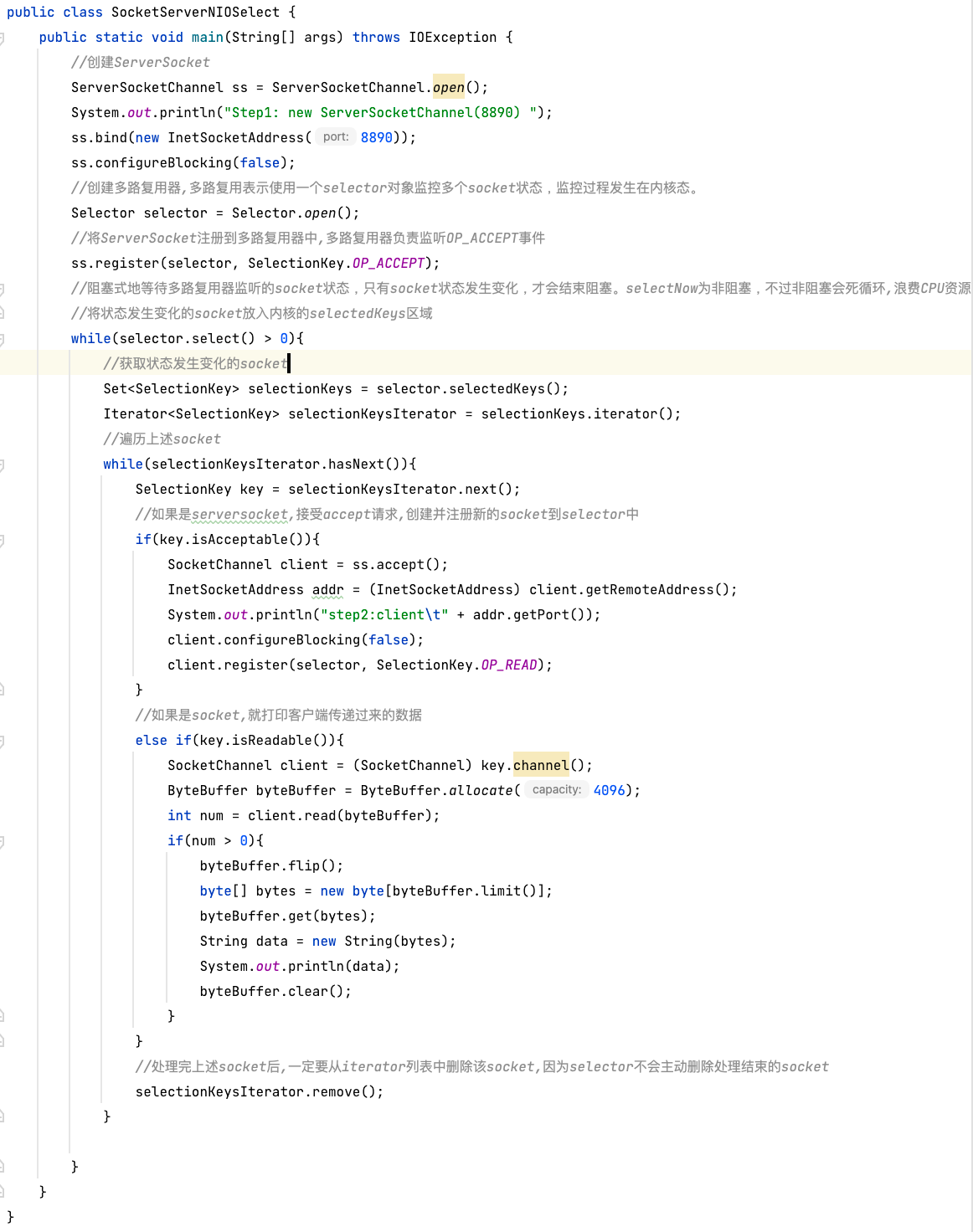
运行代码:
服务端运行,并将系统调用日志记录到socket_file文件中:
strace -ff -o socket_file /home/hadoop/jdk8/bin/java SocketServerNIOEpoll
客户端连接服务端:
nc localhost 8890
客户端发送数据:

服务端接受数据:

系统调用过程分析:
创建5号serversocket:
绑定端口并监听: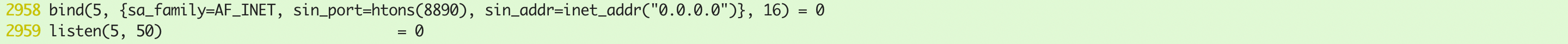
设置serversocket为非阻塞:
创建epoll文件描述符,epoll文件描述符用于注册用户态的socket:

将serversocket注册到epoll文件描述符中,阻塞等待新连接到来:
socketserver接受新连接,创建新9号socket: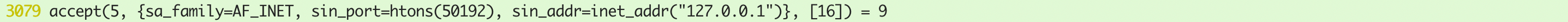
设置新的9号socket连接为非阻塞:
将9号socket注册到多路复用器epoll的8号文件描述符中(EPOLLIN就是LT,改成EPOLLIN | EPOLLET就是ET):
监控到9号文件描述符有读取事件并处理:
监控epoll文件描述符,监控红黑树中有没有socket状态变化:
4.4.4 epoll总结
内核事件通知socket状态变化,而不是主动遍历所有注册的socket,节省了cpu资源。
本文摘自 :https://blog.51cto.com/u
