 APP
APP
在文本挖掘中,我们经常有文档集合,例如博客文章或新闻文章,我们希望将它们分成自然组,以便我们理解它们。主题建模是一种对此类文档进行分类的方法。在本视频中,我们介绍了潜在狄利克雷分配LDA模型,并通过R软件应用于数据集来理解它。
视频:文本挖掘:主题模型(LDA)及R语言实现分析游记数据
文本挖掘:主题模型(LDA)及R语言实现分析游记数据
时长12:59
什么是主题建模?
主题建模是一种对文档进行无监督分类的方法,类似于对数字数据进行聚类。
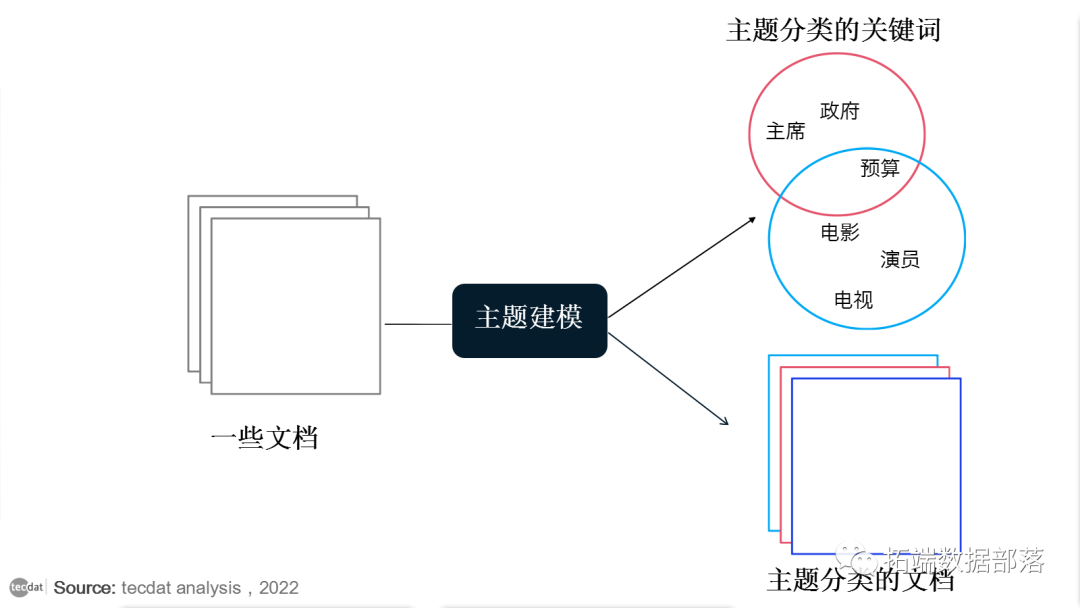
一个文档可以是多个主题的一部分,有点像模糊聚类(或软聚类),其中每个数据点属于多个聚类。
简而言之,主题建模设想了一组固定的主题。每个主题代表一组单词。主题建模 的目标是以某种方式将所有文档映射到主题,这样每个文档中的单词大部分都被那些虚构的主题捕获。
主题建模的工具和技术将文本分类或分类为每个主题的单词,这些是基于狄利克雷分布建模的。
什么是潜在狄利克雷分配?
潜在狄利克雷分配是一种无监督算法,它为每个文档为每个定义的主题分配一个值。

潜在是隐藏的另一个词(即无法直接测量的特征),而狄利克雷是一种概率分布。
我们要从数据中提取的主题也是“隐藏主题”。它还有待被发现。它的用途包括自然语言处理 (NLP)和主题建模等。
这种方法遵循与我们人类相似的思维方式。这使得 潜在狄利克雷分配 更易于解释,并且是目前最流行的方法之一。不过,其中最棘手的部分是找出主题和迭代的最佳数量。
不要将潜在狄利克雷分配与潜在判别分析(也称为 LDA)相混淆。潜在判别分析是一种有监督的降维技术,用于高维数据的分类或预处理。
为什么要进行主题建模?
主题建模提供了自动组织、理解、搜索和总结大型电子档案的方法。

它可以帮助解决以下问题:
发现收藏中隐藏的主题。新闻提供者可以使用主题建模来快速理解文章或对相似文章进行聚类。另一个有趣的应用是图像的无监督聚类,其中每个图像都被视为类似于文档。
将文档分类为发现的主题。历史学家可以使用 LDA通过分析基于年份的文本来识别归类为历史上的重要事件相关的主题。
使用分类来组织/总结/搜索文档。基于 Web 的图书馆可以使用 LDA根据您过去的阅读内容推荐书籍。例如,假设一个文档属于主题 :食品、宠物狗和健康。因此,如果用户查询“狗粮”,他们可能会发现上述文档是相关的,因为它涵盖了这些主题(以及其他主题)。我们甚至无需浏览整个文档就能够计算出它与查询的相关性。
因此,通过注释文档,基于建模方法预测的主题,我们能够优化我们的搜索过程。
潜在狄利克雷分配及其过程
潜在狄利克雷分配是一种将句子映射到主题的技术。它根据我们提供给它的主题提取某些主题集。在生成这些主题之前,LDA 执行了许多过程。
在应用该过程之前,我们有一定的规则或假设。
主题建模的 LDA 假设有两个:
首先,每个文档都是主题的混合体。我们想象每个文档可能包含来自多个主题的特定比例的单词。例如,在双主题模型中,我们可以说“文档 1 是20%的主题A和80%的主题B,而文档2是70% 的主题A和30%的主题B”。
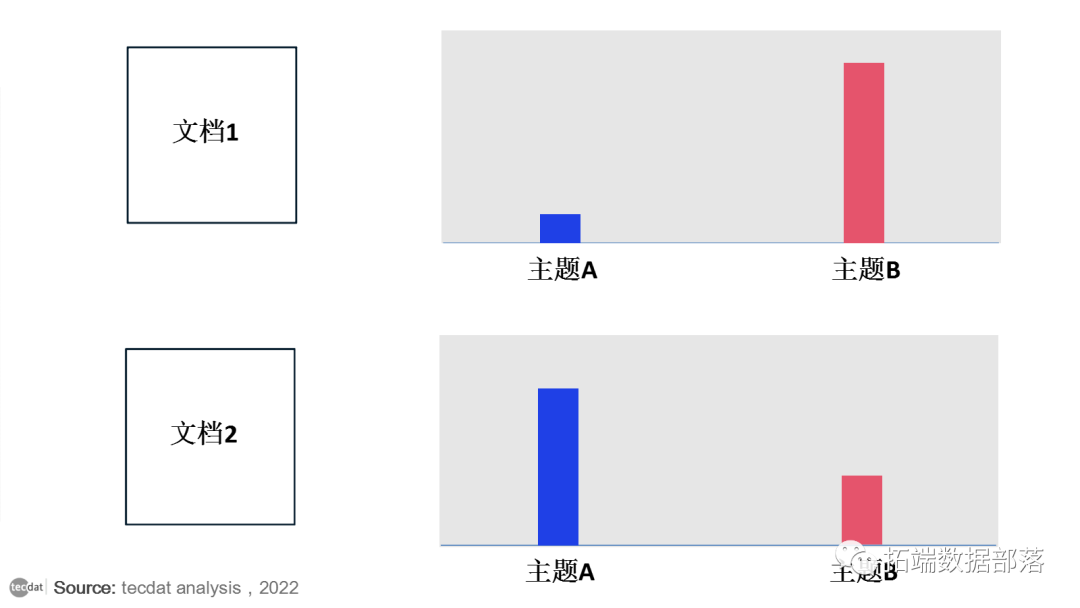
其次,每个主题都是单词的混合。例如,我们可以想象一个新闻的两个主题模型,一个主题是“政治”,一个主题是“娱乐”。政治话题中最常见的词可能是“主席”和“政府”,而娱乐话题可能由“电影”、“电视”和“演员”等词组成。重要的是,单词可以在主题之间共享;像“预算”这样的词可能会同时出现在两者中。
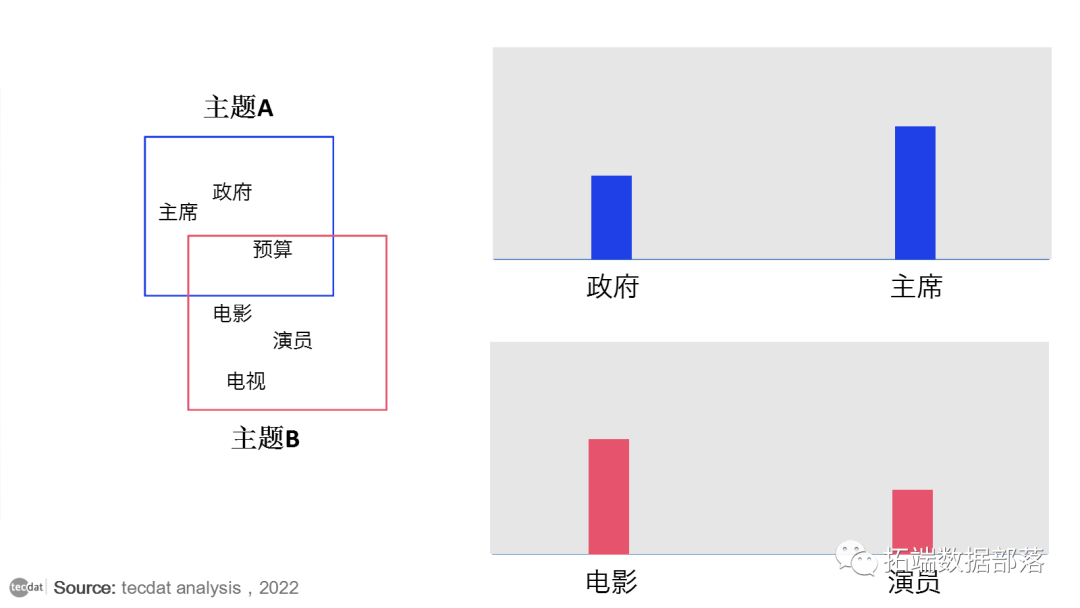
LDA 是一种同时估计这两者的数学方法:找到与每个主题相关联的词的混合,同时确定描述每个文档的主题的混合。
并且,这些主题使用概率分布生成单词。在统计语言中,文档被称为主题的概率密度(或分布),而主题是单词的概率密度(或分布)。
主题本身就是词的概率分布。
这些是用户在应用 LDA 之前必须了解的假设。
LDA 是如何工作的?
LDA 有两个部分:
属于文档的词,我们已经知道。
这属于某个主题的词或属于某个主题的单词的概率,我们需要计算。
找到后者的算法。

浏览每个文档并将文档中的每个单词随机分配给k个主题之一(k是预先选择的)。
现在我们尝试了解它的完整工作过程:
假设我们有一组来自某个数据集或随机来源的文档。我们决定要发现K 个主题,并将使用 LDA 来学习每个文档的主题表示以及与每个主题相关联的单词。
LDA 算法循环遍历每个文档,并将文档中的每个单词随机分配给 K 个主题中的一个。这种随机分配已经给出了所有文档的主题表示和所有文档的单词分布以及所有主题的单词分布。LDA 将遍历每个文档中的每个单词以改进这些主题。但是这些主题的表示并不合适。所以我们必须改进这个限制。为此,对于每个文档中的每个单词和每个主题 T,我们计算:
文档 d 中当前分配给主题 T 的单词的比例
主题 T 的分配在来自这个词的所有文档中的比例
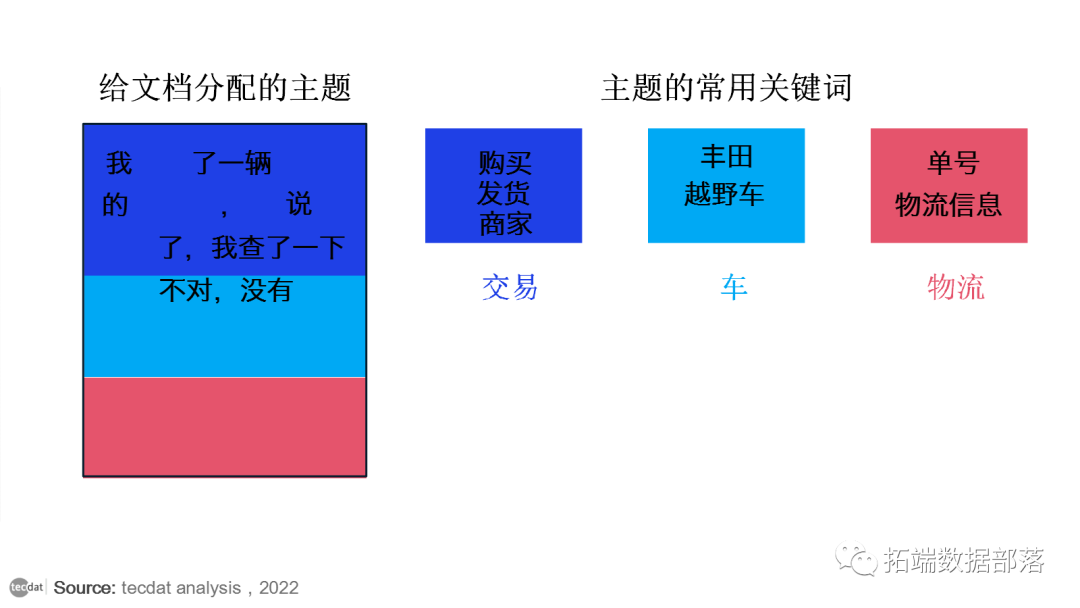
将单词重新分配给一个新主题,我们以P(主题 T | 文档 D) 乘以 P(单词| 主题 T)的概率选择主题 T,这实质上是,主题T生成的单词的概率。在多次重复上一步之后,我们最终达到了一个大致稳定的状态,即分配是可以接受的。最后,我们将每个文档分配给一个主题。我们可以搜索最有可能被分配到某个主题的单词。
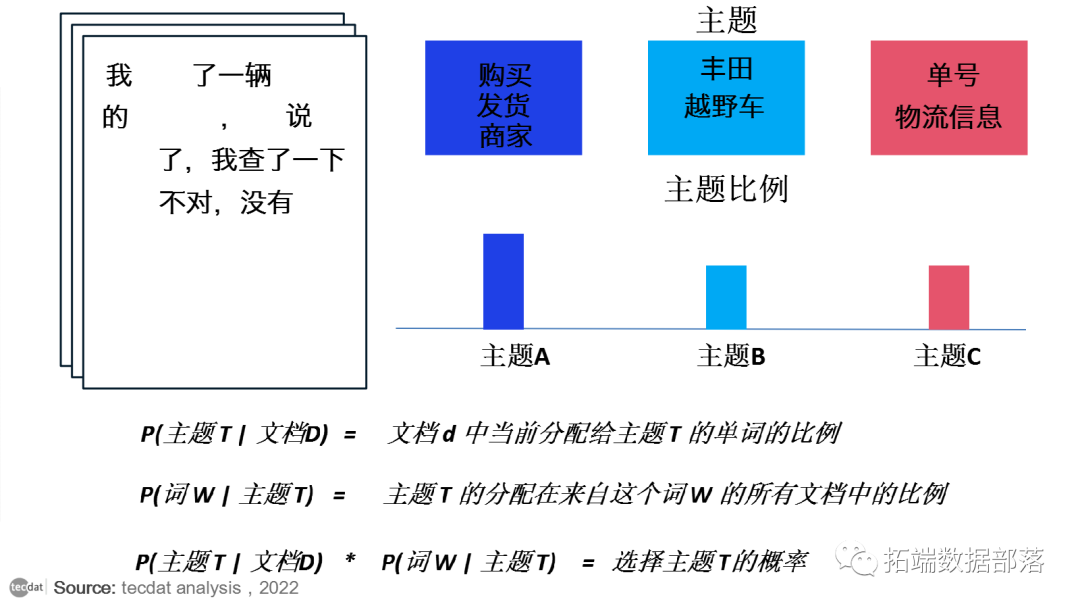
我们最终得到了输出,例如
·分配给每个主题的文档
·主题的最常用关键词
·由用户来解释这些主题。
两个重要说明:
·用户必须决定文档中存在的主题数量
·用户必须解释主题是什么
所以通常如果我们有文档集合,我们想要生成一组主题来表示文档,我们可以使用 LDA 来执行它。因为 LDA 将通过遍历每个文档来训练这些文档并将单词分配给主题。但这不是一个循环过程。这里是一个学习过程。它将遍历每个文档中的每个单词并应用上面讨论的公式。
R软件 LDA 应用
我们将尝试通过R软件将 LDA 应用于数据来更简要地理解它。
越来越多的人愿意精神消费。旅游不仅可以提升人们对外地环境和外地人文的认知,也可以放松身心、愉悦心情,是一种受欢迎的精神消费。
随着国内近些年来互联网的发展,越来越多的人开始线上消费,消费感受的推荐成为了潮流。在各个旅游平台上,越来越多的人愿意参与旅游目的地游玩感受的分享。
本文试图从马蜂窝旅游官网上就新疆这个旅游目的地游记进行感知分析。
游记表现出多元复杂的情感
通过情感分析(也称为意见挖掘),用文本挖掘和计算机语言学来识别和提取原始资料中的主观信息,分析主观信息(例如观点,情感,态度,评估,情感等),以进行提取,分析,处理,归纳和推理。
图表1
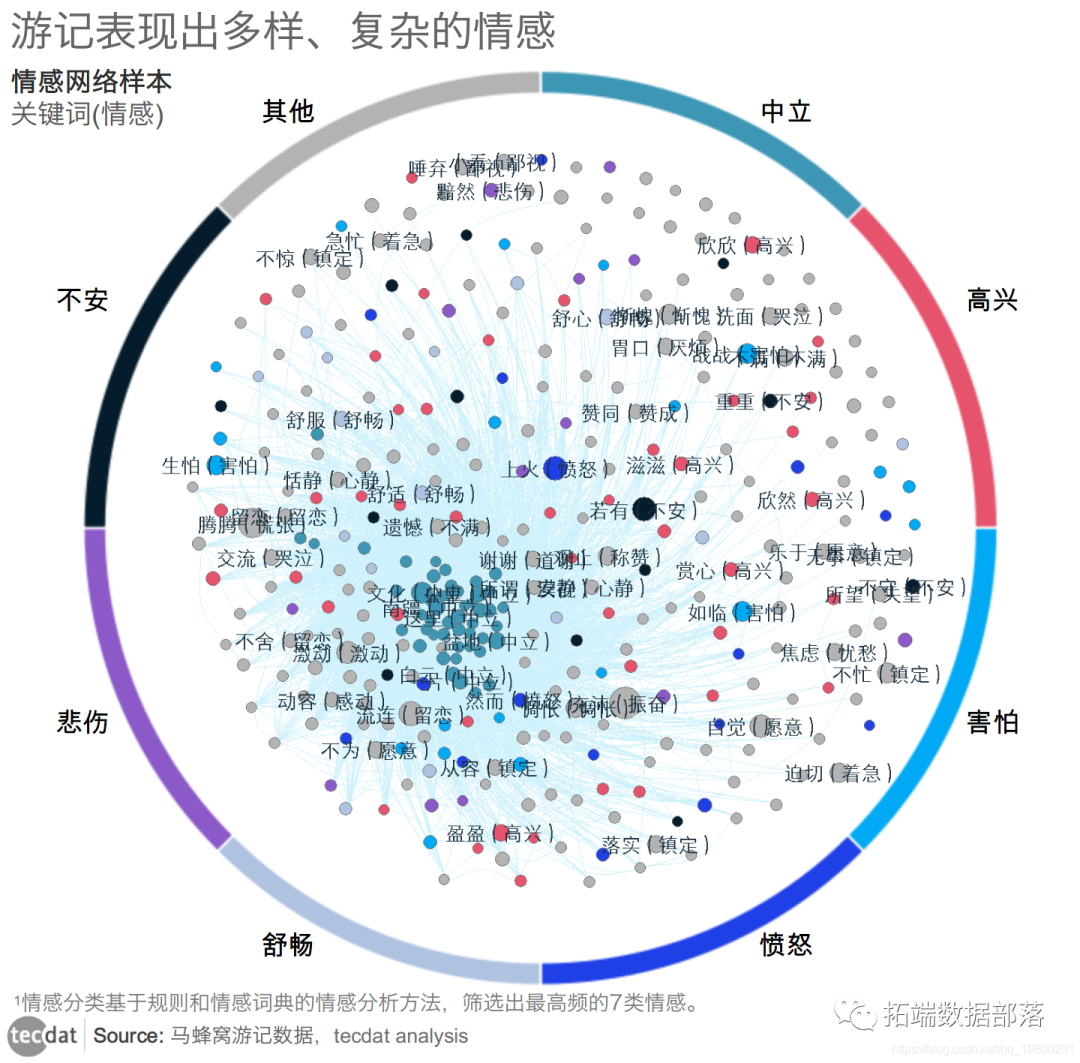
通过数据分析可知,旅客对新疆整体上正向情感还是远高于负向情感,旅游群体对新疆旅游地区还是呈现出积极的肯定态度,如舒适、恬静、赏心悦目、激动、留恋等。从词频统计看出,自然风光多,旅游对民族特色的较为关注,如:盆地、白云、沙漠、草原、南疆。当然还有吃食,如“奶酪”等等。从结果也可以看到有少量的“失望”、“惆怅”等情感,通过游记我们发现风景基本上满足了旅客的需求,但是深层次的体验项目较少,新疆旅游景点间空间跨度大、路况条件差、行车时间长、节假日拥堵排队等。新疆旅游大部分都是景区内的风景,对于自然风貌记录偏少,规划、人文旅游也偏少。情感分析可知,游客对风景、美食都很满意,有着更高的期待。
哪些游记帮助人数最多
通过游记的内容特点和帮助人数,我们通过决策树来判断哪些游记的帮助人数最多,同时也发现大多数驴友的心里出行需求。
图表2
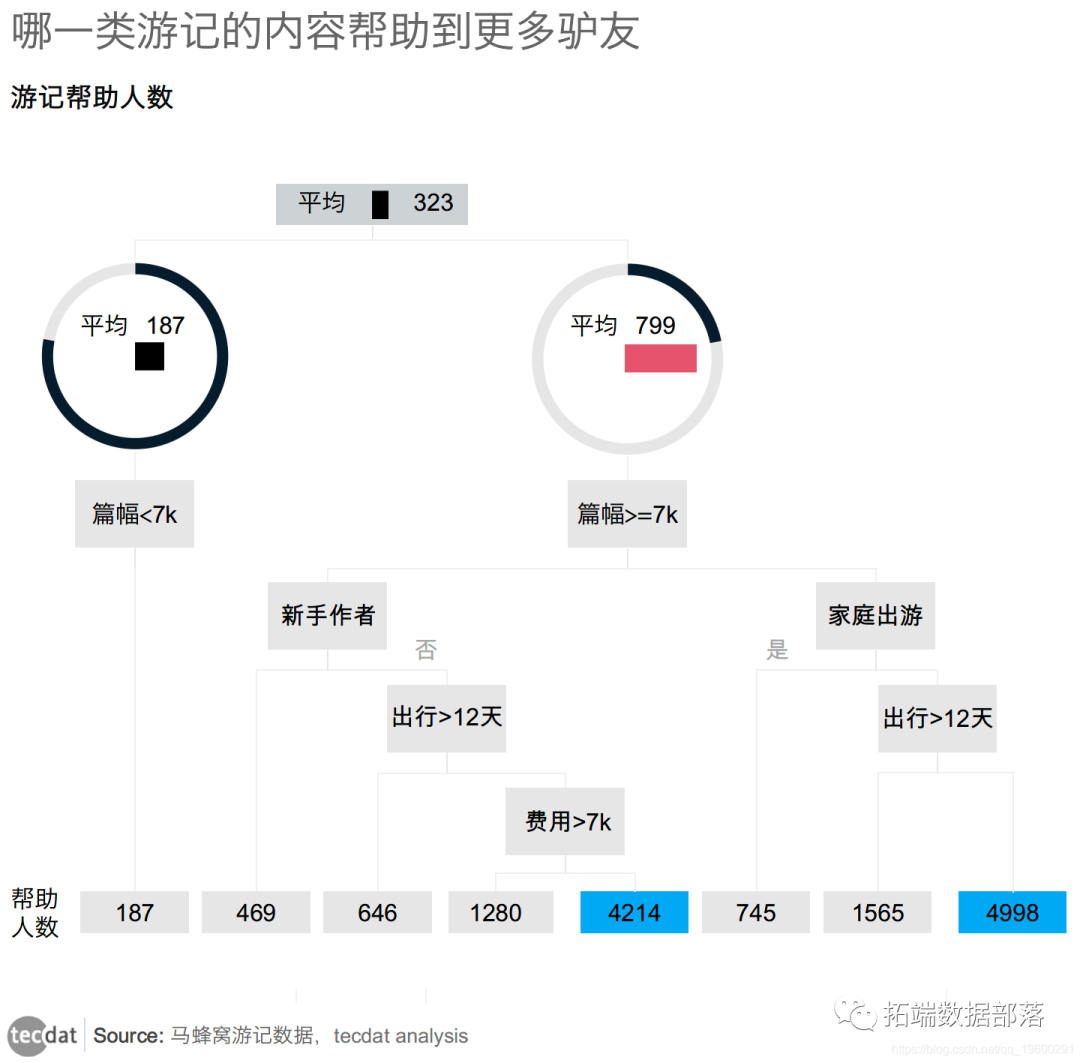
样本游记从游记篇幅、作者等级、人均花费、旅行组合、出行天数等方面反映游记的特点。游记篇幅的大小和作者等级是影响帮助人数的最重要的因素,内容详尽的游记能帮助到更多的人,经验老道的驴友的游记一般更有参考价值。旅行组合中家庭组合较少,赴疆游客以个人或朋友背包客徒步、自由行旅游为主,人均费用在7k以下,出行天数小于12天。游记的帮助人数客观地反映了驴友们旅游行程规划的心理预期,同时会对其他旅游者的决策和对旅游目的地的营销产生重要影响。
游记话题情感认知形象
接下来我们通过主题挖掘寻找游记话题和表达情感之间的关系。
图表3
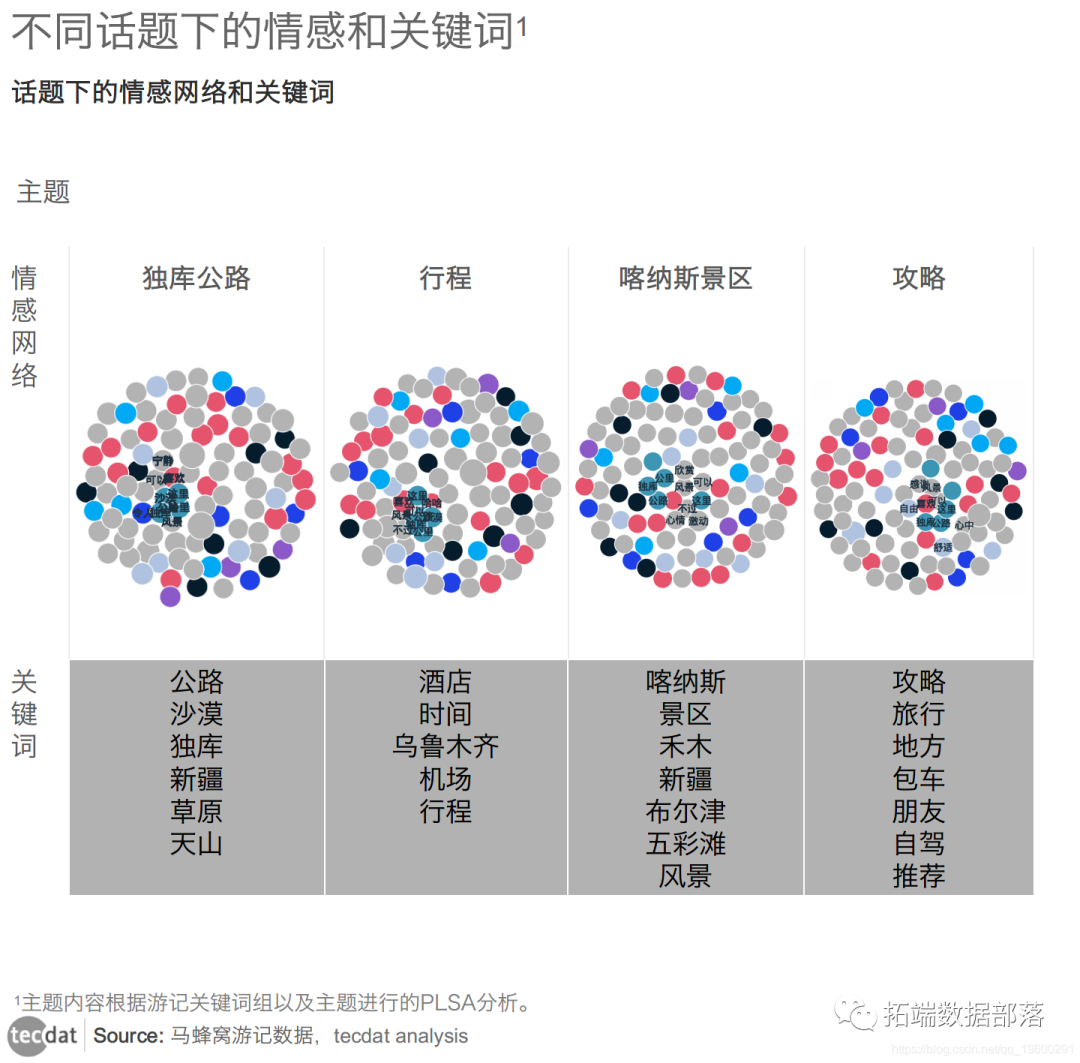
从中可以看到有两个主题是景点相关,从关键词中可以用看到驴友们关注比较多的景点是独库公路、天山、喀纳斯、禾木、布尔津、五彩滩等。“新疆”、“独库公路”、“喀纳斯”、“乌鲁木齐”是游记样本中共现频率最高的词,成为两个重要的中心节点。通常情况下,距离中心节点越近,表示与两个节点的关联越紧密。由此可见,语义网络图呈现出两个较为明显的趋势:一是“新疆”一词辐射出的语义网络除旅游景区外,更多地表现了游客对新疆“雪山”、“草原”、“景色”等旅游形象的整体情感感知:如“独特”、“宁静”等,这与新疆对外旅游宣传所采用的词语相一致; 二是“乌鲁木齐”、“风景”一词辐射出的语义网络集合了更多与行程和旅游攻略相关的信息,如“酒店”、“机场”、“包车”、“自驾”等,从游客感知视角证实了新疆旅游的旅游攻略行程信息以及乌鲁木齐作为重要的旅游集散中心在新疆旅游业发展中的地位。

本文摘自 :https://blog.51cto.com/t
