 开通会员
开通会员 2024年2月16日,OpenAI在X(原Twitter)上发布了一条消息,隆重介绍了自己的新文本转视频模型——Sora。
这个模型可以生成最长60秒的视频,并且在这个过程中,还能够自己切换镜头,甚至给出特写。下面这些,就是视频提示词译文及Sora直接根据提示词英文原文生成的“作品”。
一位时尚的女士走在亮着霓虹灯和广告牌的东京街头。她穿着黑色皮夹克、红色长裙和黑色靴子,手提一只黑色包包。她戴着太阳镜,涂着红色口红。她走路既自信又随意。街道潮湿,地面上的水能够像镜面一样反射色彩斑斓的灯光,路上有很多行人来来往往。
一段3D动画,展现一种又小又圆的毛茸茸生物在一个充满活力的、被魔法环绕的森林中探险。这种生物是兔子和松鼠的混合体,拥有柔软的蓝色皮毛和一条蓬松的带有条纹的尾巴。它沿着一条闪闪发光的小溪跳跃,眼睛充满了好奇。森林里充满了魔法元素:有发光并能变换颜色的花朵,有紫色和银色叶子的树木,以及有类似萤火虫的漂浮的光点。这个生物最终停下来与一群围绕着蘑菇跳舞的小仙子玩耍。这个生物抬头敬畏地看着一棵巨大发光树木,这棵树似乎是森林的心脏。
乍一看这些视频,你可能会以为它们是专业拍摄团队或者是动画公司制作的视频短片。在OpenAI的社区中,也不乏同样感受的网友评论称担心Sora会抢走动画师的饭碗。

图片为机器翻译后截取自:community.openai.com
还有一些人担心这样的技术会不会被用来伪造视频,甚至被用来在法庭上作伪证。
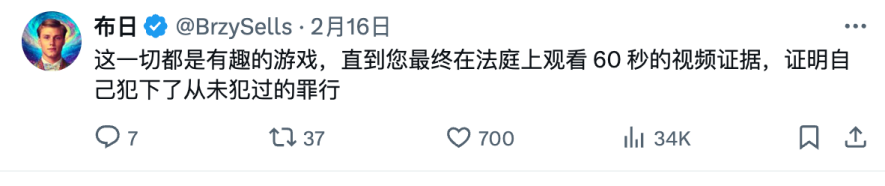
图片为机器翻译后截取自:X
那Sora是如何生成这样的视频的?它真的无所不能,会抢走人类饭碗吗?
Sora怎么生成视频?
从2022年下半年开始,Midjourney、StableDiffusion之类的应用已经可以根据文本提示词生成对应的图片了。在2023年9月,GPT4.0和DALLE3结合,也让我们能够用聊天化的方式生成、修改图片。
AI生成视频也不是什么新鲜事了。在这次的Sora发布之前,也已经有一些视频生成AI,比如Pika、Stablevideo、RunwayML等等。但与Sora相比,其他模型生成视频的时长都比较短,而且在摄像机的运动、镜头切换等方面也要弱很多。
那么,Sora又是如何生成视频的呢?
OpenAI发布了一份Sora的技术报告,在报告中提到“Sora是一个扩散模型”。

Sora是一个扩散模型,图片来源:OpenAI官网
扩散模型本身很复杂,我们不去讲具体的细节,仅仅通过一个简单的例子,大致理解扩散模型的思路。
假如我们现在有一张狗狗的照片,我们可以一步步给这张照片增加噪点,让它变得越来越模糊,最终会变成一堆杂乱的噪点。
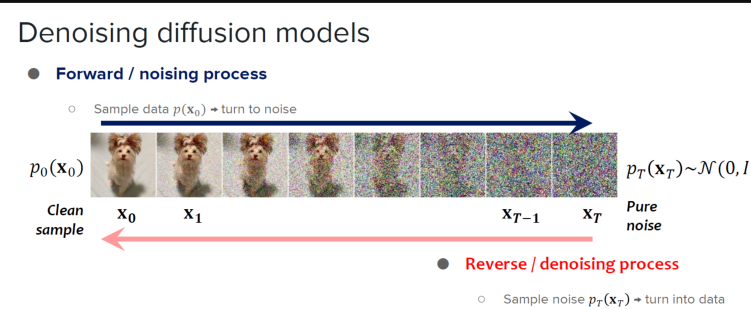
添加噪声与去除噪声,图片来源:参考资料[3]
假如把这个过程倒过来,对于一堆杂乱无章的噪点,我们同样可以一步步去除噪点,把它还原成目标图片,扩散模型的关键就是学会逆向去除噪点。
当然了,扩散模型不仅可以用来生成图片,还可以用来生成视频。比如,在Sora的技术报告中提到了,OpenAI对视频数据进行了一些转换处理,让视频数据可以直接用来训练模型,从而让Sora能够直接根据提示词生成视频。
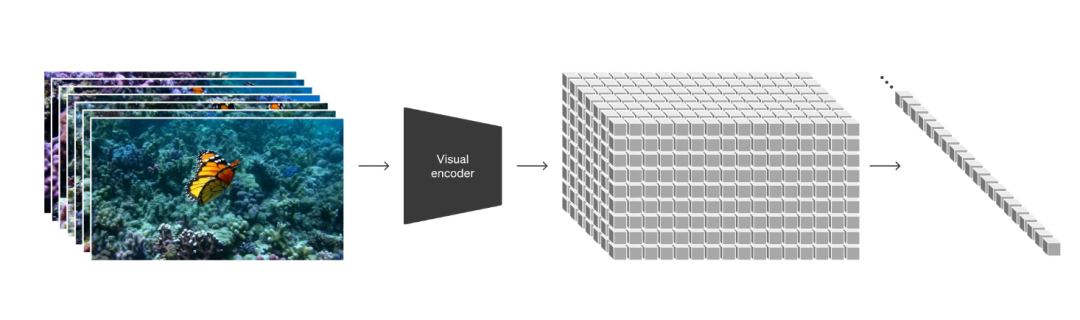
Sora对视频数据进行转换处理,图片来源:OpenAI官网
Sora强大的视频创作能力
按照OpenAI的说法,Sora“继承”了OpenAI对文本的理解能力,能够根据提示词生成出高质量的图片和视频,并且能够对视频进行向前或者向后的拓展。比如,可以基于同一个视频开头继续拓展,延伸出不一样的结尾。或者是从不同的开头引入,最终汇聚到同一个结尾。
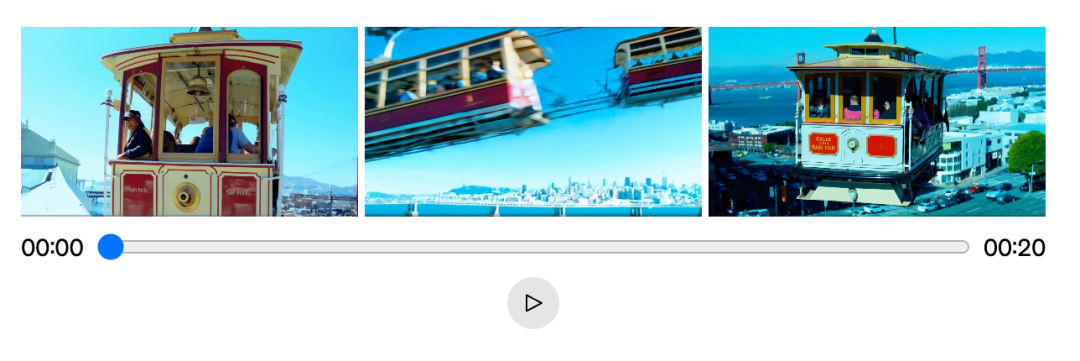
这三个视频开头最终都会走向同一个结尾,图片截取自:OpenAI官网
另外,Sora不仅可以根据文本生成视频,也可以直接输入图片或者视频,对图片和视频进行编辑调整。
比如可以将这辆行驶在普通道路上的汽车变得更“赛博朋克”一些。

图片截取自:OpenAI官网
另外,Sora也表现出了一些之前未曾想到的本领,比如它可以跟随着对象移动镜头,并且在移动镜头转换角度的时候,依然能保持周围的景象的合理、完整。
“强大的Sora”仍有一些缺陷
虽然Sora展现出了强大的能力,但现阶段它还不够完美。
并不是每一次Sora都能生成出令人满意的视频。《麻省理工科技评论(MITTechnologyReview)》主笔WillDouglasHeaven写道:“Sora发布出来的视频已经是从大量的成果中挑选出的佼佼者了。”但即便是这些“经过挑选的佼佼者”也不完美。
在Sora的技术报告中也承认,现阶段Sora生成的视频存在一些缺陷。比如,下面这个“考古工作者们挖掘出一个塑料椅”的视频片段里,这个塑料椅显然有点不遵守客观的物理规律。
另外,下面这个玻璃杯破碎的过程也不那么“科学”——在杯子破裂之前,杯子里的液体就已经流出来了。
所以,Sora还有很多需要完善的地方。但毫无疑问,目前Sora展现出来的能力已经说明了,这是一条非常有前景的道路。
Sora安全吗?
会取代人类吗?
这几天,Sora生成的视频刷爆了许多人的朋友圈,人们除了感叹Sora的厉害,同样也展现出了担忧,这些担忧集中在两个方面。
第一个担忧是:Sora生成视频的能力实在是太厉害了,如果这样的技术被用来造假,岂不是太可怕了?未来我们怎么知道看到的视频是真的还是假的?
而另一个担忧主要来自视频行业的从业者,如果Sora这样的模型普及开来,视频行业从业者是不是都要丢了饭碗?
先说说安全问题。其实,OpenAI也考虑到了Sora可能带来的安全问题。目前,Sora仅对少数人开放,在确保它不会被用来做坏事之前,Sora是不会向大众开放的。
那Sora是否会代替人类视频工作者?
可以肯定的是,Sora的出现可能会威胁一些动画素材的制作者。
比如,今年1月,《好莱坞报道》进行了一项针对300名娱乐行业领导者的调查,有四分之三的受访者表示AI会减少未来的工作岗位,未来3年内大约会有20多万个职位受到影响。而Sora优异的表现会加重这一影响。
但换一个角度想,每一次新兴技术的出现在带来威胁的同时也会带来新的机会。
包括Sora在内的视频生成AI只是一个工具,视频的创意来源还是需要人类提供。Sora或许能够帮助人类更高效地生产视频,同时,也让每一个普通人都有机会制作自己的创意视频。
参考文献
[1]https://openai.com/research/video-generation-models-as-world-simulators
[2]https://openai.com/Sora[3]https://scholar.harvard.edu/binxuw/classes/machine-learning-scratch/materials/foundation-diffusion-generative-models
[4]https://www.hollywoodreporter.com/business/business-news/ai-hollywood-workers-job-cuts-1235811009/
本文为科普中国-星空计划作品
出品|中国科协科普部
监制|中国科学技术出版社有限公司、北京中科星河文化传媒有限公司
作者丨小玮 科普创作者
审核丨秦曾昌 北京航空航天大学自动化科学与电气工程学院副教授