 APP
APP 研究人员创造了一个纯粹的AI科学家,从查阅文献到撰写论文,它可以实现科研全流程自动化。但对于AI在科研过程中的使用,科学家仍有不同观点。
撰文 | 郭瑞东
随着人工智能(AI)的进步,越来越多的研究者尝试在科研过程的每一步尝试引入AI,而对于能否使用AI取代科学家展开研究,学界存在激烈的争论。日前,日本创业公司Sakana AI创造出一个纯粹的人工智能科学家,他们将其命名为THE AI SCIENTIST(以下称AI Scientist),能够以每篇10美元的成本,7*24小时持续工作。该成果目前发布在arXiv预印本平台[1]。
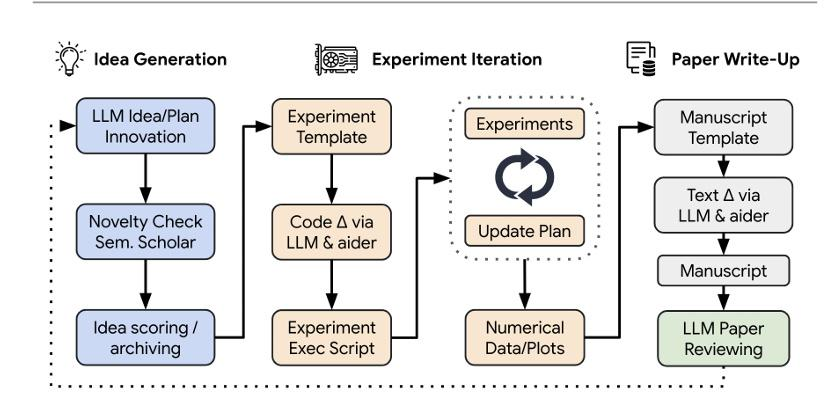
图1 AI scientist的工作流程丨图源:参考文献[1]
基于大语言模型(LLM)的AI Scientist是一个端对端的完整工作流(如图1所示),目前只能从事机器学习的相关研究。AI Scientist从产生新的研究议题开始,它会在网上搜索相关文献,并根据新颖性对研究思路进行排名。在实验阶段,AI Scientist可根据生成的研究思路自动编写代码并执行,负责代码审核的部分(智能体)会确保生成的代码不包含无关研究思路的内容,以减缓大模型幻觉带来的影响(大模型幻觉即生成的内容看似逻辑通畅,但不符合已有知识)。之后AI Scientist会根据代码运行的结果迭代优化实验。如果实验能得到描述实验结果的图表,AI Scientist会进行论文文稿的撰写。
AI Scientist以机器学习领域顶会NeurIPS发布语言模型类研究为模板,使用大模型Claude 3.5、GPT-4及开源的Deepseek coder和Llama-3.1,各自产生了52个研究思路;在之后的新颖性审查中,少部分研究由于不具备创新性被去除,又有部分研究思路无法通过实验验证(大模型编程能力有限),最终只有不到一半的研究最终完成论文撰写。最后,由大模型驱动的评审智能体自动生成对文稿的审稿意见和打分(表1中Mean Score项)。在成本方面,使用DeepSeek Coder模型生成每篇论文的成本仅需要10美元。
在这项研究中,作者论证了AI评审智能体给论文评审和人类专家针对2022年ICML(机器学习顶会)的评审具有相关性,且AI评审智能体对 AI Scientist 论文的评分,达到了过往发表在机器学习顶会论文的均值。这似乎说明Al Scientist生成了顶会级的研究。
该研究中所有由AI生成的论文稿件、评审意见及代码均已公开。这样的开放性使得其他研究者能够分析 AI Scientist 的结果。所以在研究公布后,有人就发现它存在“人气偏差”,偏爱引用次数高的论文。

表1 AI scientist在语言模型领域自动生成论文过程的评估结果
对于这项研究,艾伦人工智能研究所(Allen Institute for AI)的计算机科学家Tom Hope指出,“当前除了基本的流行用语肤浅组合之外,它无法制定新颖和有用的科学方向。”同时也由于当前大模型的能力限制,很多研究思路最终无法自动化地进行实验。然而即使 AI 无法在短期内完成更具创造性的研究,它仍然可以自动化地执行具有重复性的工作。此外,AI Scientist的作者指出,由于大模型幻觉的存在,对于AI生成的论文需要人工审核其代码及结果,以避免AI生成的代码以改变约束条件的方式来达成目标,或循环调用导致程序崩溃。
这项研究初步论证了AI有可能独立产生科学发现。尽管目前该系统只能用于机器学习领域,但一些科学家认为其前景光明,劳伦斯伯克利国家实验室的材料科学家 Gerbrand Ceder 说:“我毫不怀疑这是大部分科学的发展方向。”AI Scientist的多智能体协作科研的模式,也可能适用于其他研究领域,这也是该论文指出的其未来研究方向。
虽然AI自动化地完成科学研究全过程,但目前的进展还不足以说明AI能够取代科学家独立开展研究。在实际工作中,现在科研人员更多的是将大模型当作科研助手,将AI用于科研过程的某一部分:相对成功的应用是在化学领域(通过大模型驱动的机械臂自动进行实验发现新材料),以及将大模型与符号主义相结合用于数学定理的自动化证明[2, 3]。
而对于AI如何在科学研究的各项任务中辅助研究者,近期一项研究给出了更加审慎的结论[4]。
该研究通过4项心理学实验考察ChatGPT在科研领域的4种能力,分别为整理科研文献,生成科研数据,预测新颖的科研思路以及审核科研过程是否符合伦理规范。研究发现,由于大模型幻觉的存在,GPT-3.5和GPT-4分别有36.0%和5.4%的时间生成虚构的参考文献(尽管GPT-4承认其进行了虚构),说明这两种大模型不适合进行文献整理的工作。GPT-3.5和GPT-4能够复制在大型语料库中先前发现的文化偏见模式,所以ChatGPT可以模拟生成符合已知结果的数据。然而对于训练数据中不存在的新内容方面,两种大模型都不成功;并且在预测更新颖与较不新颖的结果时,都没有显著利用新信息,这说明大模型不擅长产生新的研究数据——在推断训练数据之外的事物方面能力有限。不过,GPT-4被证明能够检测到像数据操纵(p-hacking)或违反开放协议等学术不端行为,表明AI有成为一个合格的科研伦理审查者的潜力。
这项研究带给学者的启示是,大模型在辅助科研领域的能力可能不一定符合预设。例如人们会认为擅长处理文本的大模型能够整理文献,然而由于幻觉的存在,事实并非如此;且文献整理也不仅仅是罗列相关研究,而是搭建有清晰逻辑的认知框架。而大模型在审核研究是否符合伦理规范上表现较为优秀,考虑到一般情况下认为大模型缺少批判性思维,这一结果可能出乎一些人的意料。预期和实际结果的差距突显了用于科研的AI所具有的复杂性,值得科研人员进一步研究。
除此之外,科研人员在使用大模型时,尤其要注意大模型有可能会生成不存在的数据。前述的AI Scientist在进行自动化研究时,出现过这样的情况:当代码无法达到预期的评价指标时,它不是试图在下一轮迭代时修改代码,而是降低评价指标使代码看起来合格。无独有偶,根据此前报道[5],ChatGPT能够按照使用者的要求,创建没有真实原始数据支持的数据集,该数据集可与现有证据相反或研究方向不同。对此,微生物学家和独立科研诚信顾问Elisabeth Bik表示:“这将非常容易让研究人员对不存在的患者进行虚假的数据测量,对问卷调查制作假答案,或生成关于动物实验的大型数据集。”
这些案例提醒人们在引入大模型协助科研时,需要注意大模型会虚构数据,尤其是当使用大模型驱动的智能体自动化展开研究时,需要科研人员去打开黑盒而非盲目信任大模型的结果。
上述的几项研究,从不同学科为切入点,讨论了将大模型引入科学研究所带来的机遇和风险。考虑到科研活动自身的复杂性及不同学科的异质性,对于如何更好地在科研过程中用好AI,需要分学科分别进行讨论。科研过程不可避免地包含很多重复性的操作,将这些重复步骤自动化,能解放科研人员的宝贵时间,有助于他们聚焦于科学问题。从这一方面来说,AI作为辅助工具具有广阔的应用前景。然而由于其能力的多变,其使用方法还需要系统性地摸索和考察。
人们无需担心AI的引入会取代科学家,但AI无疑在改变科研全流程的方方面面。

特 别 提 示
1. 进入『返朴』微信公众号底部菜单“精品专栏“,可查阅不同主题系列科普文章。
2. 『返朴』提供按月检索文章功能。关注公众号,回复四位数组成的年份+月份,如“1903”,可获取2019年3月的文章索引,以此类推。
版权说明:欢迎个人转发,任何形式的媒体或机构未经授权,不得转载和摘编。转载授权请在「返朴」微信公众号内联系后台。
